

Top
Author
Updated
31 Jul 2025Form Number
LP1711PDF size
13 pages, 620 KBSubscribed to LP1711.
Thank you for your feedback.
Abstract
Server reliability, availability, and serviceability (RAS) are crucial issues for modern enterprise IT shops that deliver mission-critical applications and services, and application delivery failures can be extremely costly per hour of system downtime. Intel Xeon Scalable processors running on ThinkSystem servers continue to be at the top of the industry in regards to RAS features. This article explains the importance of RAS features on a server and a list of Key RAS features on the latest ThinkSystem servers Lenovo offers to customers looking to minimize downtime in their data center.
Change History
Changes in the July 31, 2025 update:
- Changed the following under - Server RAS Defined section
- New image for "Hourly Cost of Downtime"
- New image for "Unplanned Downtime by Server Hardware Platform in November 2024"
- Added 6th Gen processors to the table of RAS features - RAS features with Intel Xeon Scalable processors section
Introduction
Applications such as database, enterprise resource planning (ERP), customer resource management (CRM), and business intelligence (BI) applications need to be available 24 x 7 on a wide area or global basis. In addition, the likelihood of such failures increases statistically with the size of the servers, data, and memory required for these deployments.
While clustering and virtualization can help meet availability requirements, they are not adequate solutions for very large databases, BI, and high-end transactional systems. A failure affecting a single core business application can easily cost hundreds of thousands or even millions of dollars per hour. All this leads to a need for scalable and highly resilient servers that are well suited for critical business applications and large-scale consolidation.
Always On
Time is money. Even a few minutes of downtime can result in significant costs and cause internal business operations to come to a standstill. Downtime can also adversely impact a company’s relationship with its customers, business suppliers and partners. Reliability or lack thereof can potentially damage a company’s reputation and result in lost business.
The growth of new applications has ratcheted database processing and business analytics to the top of the list for server workloads. These workloads demand continuous availability from the enterprise platforms on which they run.
"Always on" has become a global requirement and impacts many aspects of our lives:
- Maximize productivity - Manufacturers need to keep their production line up and running. System downtime should not interrupt it.
- Control access - Facility Security companies prevent external threats to organizations. Security application downtime shouldn't be an internal threat.
- Protect profit - Retailers have sales targets to meet day in, day out. Transaction system downtime shouldn’t get in the way.
- Protect lives - First Responders take care of emergencies 24 x 7 x 365. Application downtime shouldn’t be one of them.
- Ensure quality care and privacy - Healthcare Institutions need to access patient information and be HIPPA compliant all the time. System downtime shouldn’t compromise either one.
- Process transactions - Financial Services organizations manage thousands of transactions a second. Processing system downtime simply can’t happen
Server RAS Defined
RAS in relation to servers is defined as follows:
Reliability – Reducing the mean time between hardware failures and ensuring data integrity. Data integrity is protected through error detection and correction — or, if not correctable, error containment
- Error Detection and Self-Healing
- Minimizes outage opportunities
- Correct results continuously
Availability – Refers to uninterrupted system and application operation even in the presence of uncorrectable errors
- Reduce frequency and duration of outages
- Self-diagnosing: work around faulty components or “self-heal”
- Never stops or slows down
Serviceability – Means a system can be maintained without disrupting operation. This capability requires both thoughtful platform design and innovative systems management.
- Avoid repeat failures with accurate diagnostics
- Concurrent repair on higher failure rate items
- Easy to repair and upgrade
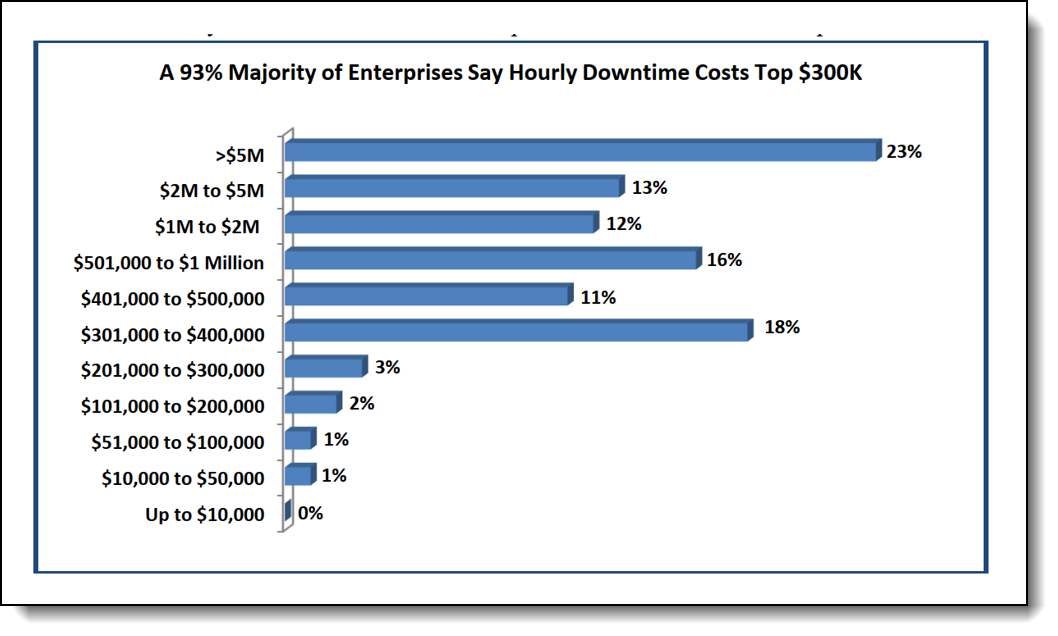
Unplanned Downtime by Hardware Platform
According to ITIC, Lenovo ThinkSystem and IBM lead the way for unplanned downtime
- Lenovo ThinkSystem: 315 milliseconds
- Cisco UCS: 20 minutes
- HPE Superdome: 1.35 minutes
- Dell PowerEdge: 20 minutes
- HPE ProLiant: 30 minutes
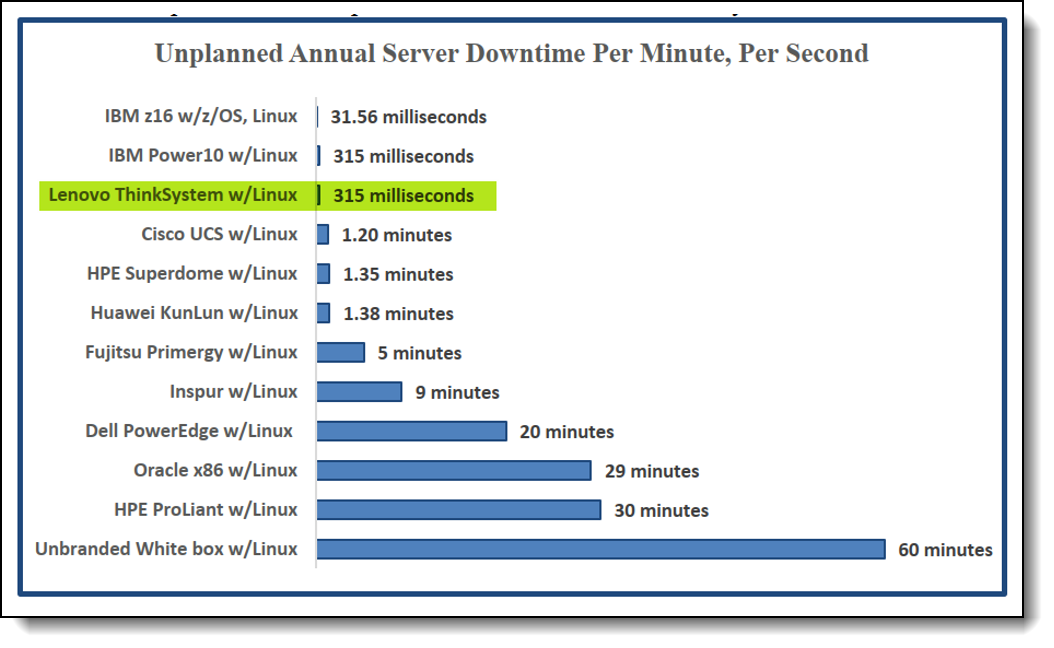
Figure 2. Unplanned Downtime by Server Hardware Platform in November 2024 (from ITIC 2024 Global Server Hardware/Server OS Reliability Survey)
RAS features with Intel Xeon Scalable processors
The following table is a list of Key RAS Features of the Intel Xeon Scalable processors on the Lenovo ThinkSystem servers.
* See additional information about ADDDC below
** Runtime Post Package Repair (PPR) is not supported by Sierra Forest but Granite Rapids supports it
All ThinkSystem servers with Intel Xeon Scalable processors support the ADC (SR or Single Region) and ADDDC (MR or Multiple Region) feature which can support DRAM sub-region(s) sparing at Bank and/or full Rank granularity, compared to the memory rank sparing feature.
Details of Adaptive Double DRAM Device Correction (ADDDC) from the Intel article "New Reliability, Availability, and Serviceability (RAS) Features in the Intel® Xeon® Processor Family" https://www.intel.com/content/www/us/en/developer/articles/technical/new-reliability-availability-and-serviceability-ras-features-in-the-intel-xeon-processor.html
Intel Xeon introduces an innovative approach in managing errors that the DDR4 DRAM DIMM may induce through the life of the product. ADDDC is deployed at runtime to dynamically map out the failing DRAM device and continue to provide SDDC ECC coverage on the DIMM, translating to longer DIMM longevity. The operation occurs at the fine granularity of DRAM Bank and/or Rank to have minimal impact on the overall system performance.
With the advent of ADDDC, the memory subsystem is always configured to operate in performance mode. When the number of corrections on a DRAM device reaches the targeted threshold value, with help from the UEFI runtime code, the identified failing DRAM region is adaptively placed in lockstep mode where the identified failing region of the DRAM device is mapped out of ECC. Once in ADDDC, cache line ECC continues to cover single DRAM (x4) error detection and apply a correction algorithm to the nibble.
Dependent on the processor SKU, each DDR4 channel supports one to two regions that can manage one or two faulty DRAMs, at Bank and/or full Rank granularity. The dynamic nature of the operation makes the performance implications of the lockstep operation on the system to be material only after the DRAM device is detected to be failing. The overall lockstep impact on system performance is now a function of the number of bad DRAM devices on the channel, with the worst-case scenario of two bad Ranks on every DDR4 channel.
The Silver/Bronze SKUs offer Adaptive Data Correction (ADC [SR]), at Bank granularity, and the Platinum/Gold SKUs offer Adaptive Double DRAM Device Correction (ADDDC [MR]), at Bank and Rank granularity, with additional hardware facilities for device map-out.
Further reading
For further analysis of the reliability of Lenovo servers, see the latest ITIC report, available from:
ITIC 2023-2024 Global Server Hardware Reliability & Server Security Survey Results:
https://lenovopress.lenovo.com/lp1117-itic-reliability-study
About the authors
Randall Lundin is a Senior Product Manager in the Lenovo Infrastructure Solution Group. He is responsible for planning and managing ThinkSystem servers. Randall has also authored and contributed to numerous Lenovo Press publications on ThinkSystem products.
Jason (Zhijun) Liu is a Principal Engineer and Senior UEFI Architect at Lenovo Infrastructure Solutions Group. Jason provides high-level infrastructure design support for Lenovo ThinkSystem UEFI firmware and leads the enabling, customization and innovation of new technologies into UEFI firmware. Jason also leads Reliability, Availability and Serviceability (RAS) architecture design and Secure feature design for ThinkSystem firmware.
Trademarks
Lenovo and the Lenovo logo are trademarks or registered trademarks of Lenovo in the United States, other countries, or both. A current list of Lenovo trademarks is available on the Web at https://www.lenovo.com/us/en/legal/copytrade/.
The following terms are trademarks of Lenovo in the United States, other countries, or both:
Lenovo®
ThinkSystem®
The following terms are trademarks of other companies:
Intel®, the Intel logo and Xeon® are trademarks of Intel Corporation or its subsidiaries.
IBM® is a trademark of IBM in the United States, other countries, or both.
Other company, product, or service names may be trademarks or service marks of others.
Configure and Buy
Please select a locale
Full Change History
Changes in the July 31, 2025 update:
- Changed the following under - Server RAS Defined section
- New image for "Hourly Cost of Downtime"
- New image for "Unplanned Downtime by Server Hardware Platform in November 2024"
- Added 6th Gen processors to the table of RAS features - RAS features with Intel Xeon Scalable processors section
Changes in the April 22, 2024 update:
- Changed the explanation of the Rank/Multi Rank Sparing & DRAM sparing row - RAS features with Intel Xeon Scalable processors section
Changes in the April 12, 2024 update:
- Changed the explanation of the Rank/Multi Rank Sparing & DRAM sparing row - RAS features with Intel Xeon Scalable processors section
Changes in the February 28, 2024 update:
- Added 5th Gen processors to the table of RAS features - RAS features with Intel Xeon Scalable processors section
Changes in the April 24, 2023 update:
- Added additional information about Adaptive Double DRAM Device Correction (ADDDC) - RAS features with Intel Xeon Scalable processors section
First published: March 21, 2023
Course Detail
Employees Only Content
The content in this document with a is only visible to employees who are logged in. Logon using your Lenovo ITcode and password via Lenovo single-signon (SSO).
The author of the document has determined that this content is classified as Lenovo Internal and should not be normally be made available to people who are not employees or contractors. This includes partners, customers, and competitors. The reasons may vary and you should reach out to the authors of the document for clarification, if needed. Be cautious about sharing this content with others as it may contain sensitive information.
Any visitor to the Lenovo Press web site who is not logged on will not be able to see this employee-only content. This content is excluded from search engine indexes and will not appear in any search results.
For all users, including logged-in employees, this employee-only content does not appear in the PDF version of this document.
This functionality is cookie based. The web site will normally remember your login state between browser sessions, however, if you clear cookies at the end of a session or work in an Incognito/Private browser window, then you will need to log in each time.
If you have any questions about this feature of the Lenovo Press web, please email David Watts at dwatts@lenovo.com.





