

Top
Published
16 Jul 2024Form Number
LP1988PDF size
15 pages, 676 KBSubscribed to LP1988.
Thank you for your feedback.
Table of Contents
Abstract
Lenovo is guided by a principle of enabling smarter technology and AI for all and becoming the most trusted partner in intelligent transformation. These principles drive our commitment to expedite innovation by empowering global partners and customers to develop, train, and deploy AI at scale across various industry verticals with utmost safety and efficiency. Enterprise adoption of AI is increasing, and many adopters are successful in getting ROI and seeing tangible business value. The early adoption of Generative AI across industries shows transformation in workforce to improve productivity and efficiency, generating creative content, extracting information from a variety of documents, and integrating with other AI/ML use cases.
Lenovo on-prem infrastructure solutions influence AI adoption rate with a choice of servers, storage, accelerators, and AI software to address training and inference performance, costs, data sovereignty, and compliance. Lenovo V3 systems with 4th and 5th gen Intel® Xeon® Scalable Processors and VMware Cloud Foundation software stack is an ideal platform for developing and deploying AI/ML workloads. Intel Xeon Scalable processors with powerful, integrated AI accelerators can address fine tuning and inferencing performance objectives while reducing system complexity and deployment and operational costs for greater business return. The solution empowers CPU-based AI/ML deployment without compromising performance and without investment in expensive GPU accelerators.
Lenovo V3 Systems with Intel 4th and 5th Gen Scalable Processors
Lenovo ThinkSystem SR650 V3 2U and SR630 V3 1U servers and ThinkAgile VX650 V3 2U and VX630 V3 1U hyperconverged solutions with VMware vSAN powered by 4th and 5th gen Intel Xeon Scalable processors are optimized for AI workloads and Accelerated by Intel offerings. Lenovo V3 systems support up to 64 cores per socket with 5th Gen Intel Xeon processors and up to 60 cores per socket with 4th Gen processors.
ThinkAgile VX V3 systems are factory-integrated, pre-configured ready-to-go integrated systems built on proven and reliable Lenovo ThinkSystem servers that provide compute power for a variety of workloads and applications and are powered by industry-leading hyperconverged infrastructure software from VMware. It provides quick and convenient path to implement a hyperconverged solution powered by VMware Cloud Foundation (VCF) or VMware vSphere Foundation (VVF) software stacks with "one-stop shop" and a single point of contact provided by Lenovo for purchasing, deploying, and supporting the solution.
Intel Optimized AI Libraries & Frameworks
Intel provides a comprehensive portfolio of AI development software including data preparation, model development, training, inference, deployment, and scaling. Using optimized AI software and developer tools can significantly improve AI workload performance, and developer productivity, and reduce compute resource usage costs. Intel® oneAPI libraries enable the AI ecosystem with optimized software, libraries, and frameworks. Software optimizations include leveraging accelerators, parallelizing operations, and maximizing core usage.
Intel® Advanced Matrix Extensions (Intel® AMX)
Intel® AMX is a new set of instructions designed to work on matrices and it enables AI fine-tuning and inference workloads to run on the CPU. Its architecture supports bfloat16 (training/inference) and int8 (inference) data types and Intel provides tools and guides to implement and deploy Intel AMX. The Intel AMX architecture is designed with two components,
- Tiles: These consist of eight two-dimensional registers, each 1 kilobyte in size, that store large chunks of data.
- Tile Matrix Multiplication (TMUL): TMUL is an accelerator engine attached to the tiles that performs matrix-multiply computations for AI.
Refer more information about Intel AMX here.
With integrated Intel AMX on 4th and 5th gen Intel Xeon Scalable processors, many AI inferencing and fine-tuning workloads, including many Generative AI use cases, can run optimally.
Intel AI software and optimization libraries provide scalable performance using Intel CPUs and GPUs. Many of the libraries and framework extensions are designed to leverage the CPU to provide optimal performance for machine learning and inference workloads. Developers looking to leverage these tools can download the AI Tools from AI Tools Selector.
Table 1: Intel AI optimization software and development tools
|
Software/Solution |
Details |
|
Intel® oneAPI Library |
· Intel® oneAPI Deep Neural Network Library (oneDNN) · Intel® oneAPI Data Analytics Library (oneDAL) · Intel® oneAPI Math Kernel Library (oneMKL) · Intel® oneAPI Collective Communications Library (oneCCL) |
|
MLOPs |
Cnvrg.io is a platform to build and deploy AI models at scale |
|
AI Experimentation |
SigOpt is a guided platform to design experiments, explore parameter space, and optimize hyperparameters and metrics |
|
Intel® Extension for PyTorch |
Intel Extension for PyTorch extends PyTorch with the latest performance optimizations for Intel hardware, also taking advantage of Intel AMX |
|
Intel Distribution for Python |
· Optimized core python libraries (scikit-learn, Pandas, XGBoost) · Data Parallel Extensions for Python. · Extensions for TensorFlow, PyTorch, PaddlePaddle, DGL, Apache Spark, and for machine learning · NumPy, SciPy, Numba, and numba-dpex. |
|
Intel® Neural Compressor |
This open-source library provides a framework-independent API to perform model compression techniques such as quantization, pruning, and knowledge distillation, to reduce model size and speed up inference. |
VMware Cloud Foundation
VMware Cloud Foundation (VCF) is a multi-cloud platform supporting virtual machines and containerization of workloads on common virtualized infrastructure built on top of vSphere, vSAN, and NSX. The suite includes VMware Aria Suite for private/hybrid cloud management and VMware Tanzu for Kubernetes workloads. Refer more details in VMware Cloud Foundation reference design here.
VMware Private AI with Intel
VMware Private AI with Intel solution enables enterprises to develop and deploy classical machine learning models and generative AI applications on the infrastructure powered by Intel AI software and built-in accelerators and managed by VMware Cloud Foundation. VCF provides integrated security capabilities to secure AI, and it is an ideal platform for training and running private LLMs across business functions in an enterprise. The Intel AI software suite and VMware Cloud Foundation are validated on Lenovo ThinkSystem and ThinkAgile servers with 4th and 5th gen Intel Xeon Scalable processors and private LLMs or generative AI models can be deployed at scale along with other AI use cases.
Intel AMX instructions are supported on vSphere 8.0 and above with VMs using virtual HW version 20 and above. The guest OS running Linux should use kernel 5.16 or later and if Tanzu Kubernetes is used, the worker nodes should use Linux kernel 5.16 or later.
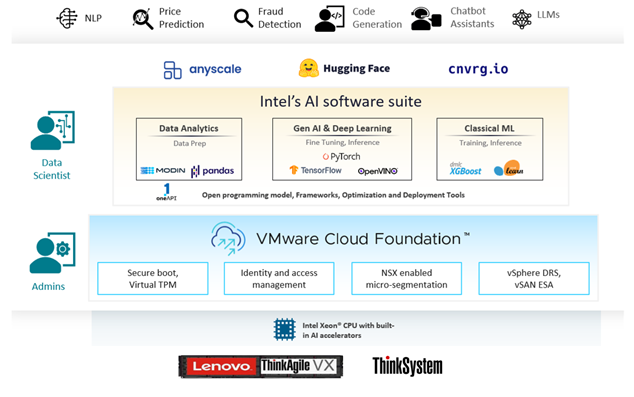
Figure 1. VMware Private AI with Intel on Lenovo ThinkAgile VX and ThinkSystem Servers
Llama2 LLM Inference Performance with 4th Gen Intel Xeon Scalable Processors
The Generative AI inference testing with Llama2 7B and 13B model was done on ThinkAgile VX650 V3 server with 4th Gen Intel Xeon Scalable processors by Intel on May 14, 2024. The test was carried out with different input token sizes 32/256/1024/2048 with varying batch sizes of 1-16 to simulate concurrent requests with static output token size 256. The objective of the testing is to validate different scenario's performance with acceptable latency of less than 100ms latency and to compare the results with/without Intel AMX.
The test and inference serving is targeted on a single node with local storage running ESXi 8.0 U2 and two Ubuntu 22.04.4 guest virtual machines. The model performance can be scaled out by using multiple nodes, but it is not in scope of the current version.
Table 2. Test Hardware Configuration
|
Server |
Lenovo ThinkAgile VX650 V3 CN |
|
Processor |
2x Intel Xeon Gold 6448H processors, 2x32C, 2.4 GHz |
|
Memory |
1024GB (16x64GB DDR5 4800 MT/s [4800 MT/s]) |
|
NIC |
1x ThinkSystem Mellanox ConnectX-6 Lx 10/25GbE SFP28 2-Port PCIe Ethernet Adapter |
|
Disk |
1x ThinkSystem M.2 7450 PRO 960GB Read Intensive NVMe PCIe 4.0 x4 NHS SSD 8x ThinkSystem 2.5" U.3 7450 MAX 6.4TB Mixed Use NVMe PCIe 4.0 x4 HS SSD |
|
Hyperthreading |
Intel® Hyper-Threading Technology Enabled |
|
Turbo |
Intel® Turbo Boost Technology Enabled |
|
NUMA Nodes |
2 |
|
BIOS |
2.14 |
|
Microcode |
0x2b000461 |
|
Hypervisor |
VMware ESXi 8.0 U2 22380479 |
|
BIOS Settings |
Performance (BIOS and ESXi profile), Max C-State =C0/C1 |
|
Guest VM |
Ubuntu 22.04.4 LTS, 5.15.0-105-generic |
|
VM HW Version |
· VM vHardware gen 21 - Intel AMX available for guest OS · VM vHardware gen 17 - Intel AMX is not available for guest OS; Intel® Advanced Vector Extensions 512 (Intel® AVX-512) VNNI is available |
|
VM Configuration (Local Storage Testing) |
60vCPU (reservation) 400GB RAM (reservation) vmxnet3 Latency sensitivity mode:high multi socket scenario (30 cores per AI instance) |
|
Container Configuration (vSAN ESA Testing) |
112 VCPU 128 GB Memory 240 GB storage Number of containers =1 VCF 5.2.0 VMware Tanzu 1.28.3 |
LLM Inference Results on Virtual Machines with Local Storage
The tests and inference serving is targeted on single node with local storage running ESXi 8.0 U2 and two Ubuntu 22.04.4 guest virtual machines. The model performance can be scaled out by using multiple nodes, but it is not in scope of the current version.
Table 3. Test Configuration
|
Workload |
LLM Inference |
|
Application |
Intel Extension for PyTorch (IPEX) with DeepSpeed |
|
Libraries |
IPEX 2.2 with DeepSpeed 0.13; Pytorch 2.2 (public releases) |
|
Script |
|
|
Test Run settings |
· warm up steps = 5 · steps = 50 · -a flag (Max number of threads (this should align with · OMP_NUM_Threads)) = 60 · e (Number of inter threads: e=1: run 1 thread per core; e=2: run two threads per physical core) = 1 |
|
Model |
Llama2 7B & 13B |
|
Dataset |
IPEX.LLM prompt.json (subset of pile-10k) |
|
Batch Size |
1/2/4/8/16 |
|
Precision |
bfloat16 |
|
Framework |
IPEX 2.2 (public release) |
|
# of instances |
2 |
Llama2 7B Performance Results with/without Intel AMX
Figure 2 shows the 2nd token average latency performance with Intel AMX on 4th gen Intel Xeon Scalable processors for Llama 7B model and Figure 3 shows the results without Intel AMX. The test with Intel AMX shows up to 42% in 2nd token latency for the scenario with input/output token size 32/256. The 2nd token latency for different concurrent requests scenarios (batch sizes 1/2/4/8/16) with input/output token size of 32/256, and 256/256 are within an acceptable threshold of 100 milliseconds and it shows significant throughput increase can be achieved with Intel AMX. The results without Intel AMX show all the scenarios with batch size 8/16 exceeded the 100 milliseconds threshold.
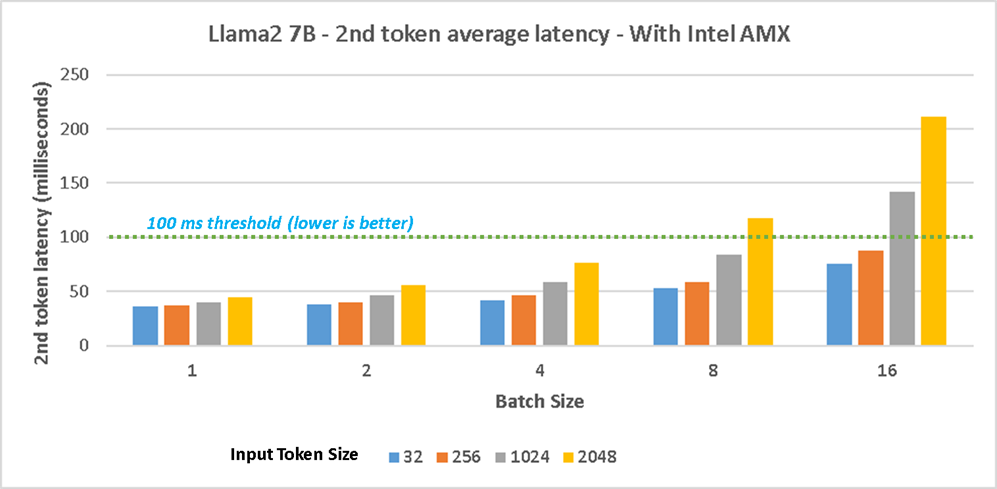
Figure 2. Llama2 7B testing with 4th Gen Intel Xeon CPUs with Intel AMX - 2nd token average latency
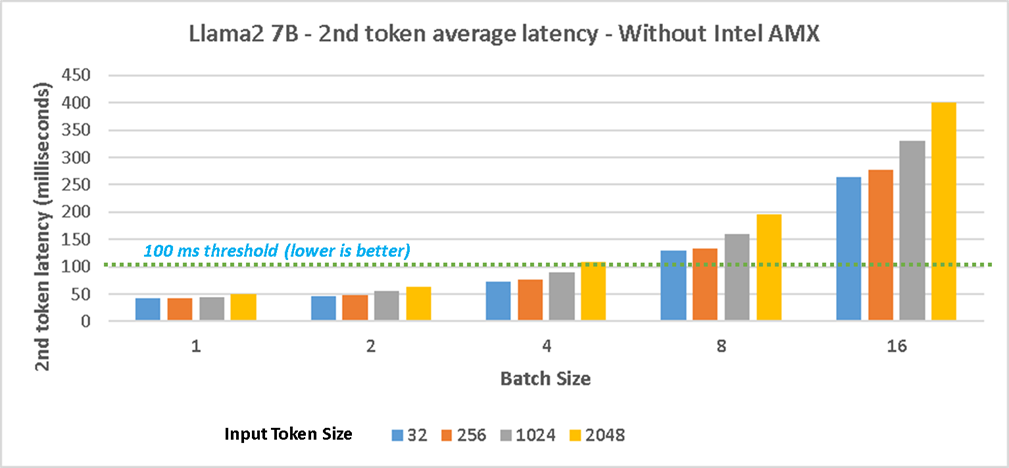
Figure 3. Llama2 7B testing with 4th Gen Intel Xeon CPUs without Intel AMX - 2nd token average latency
Llama2 13B Performance Results with/without Intel AMX
Figure 4 shows the 2nd token average latency performance with Intel AMX on 4th gen Intel Xeon Scalable processors for Llama 13B model and Figure 5 shows the results without Intel AMX. The test with Intel AMX shows up to 18% decrease in 2nd token latency for the scenario with input/output token size 32/256. The 2nd token latency for different concurrent user scenarios (batch sizes 1/2/4/8) with input token size of 32/256 are within an acceptable threshold of 100 milliseconds and it shows considerable throughput increase can be achieved with Intel AMX. The results without Intel AMX shows most of the scenarios with batch size 4/8/16 exceeded the 100ms next token latency threshold.
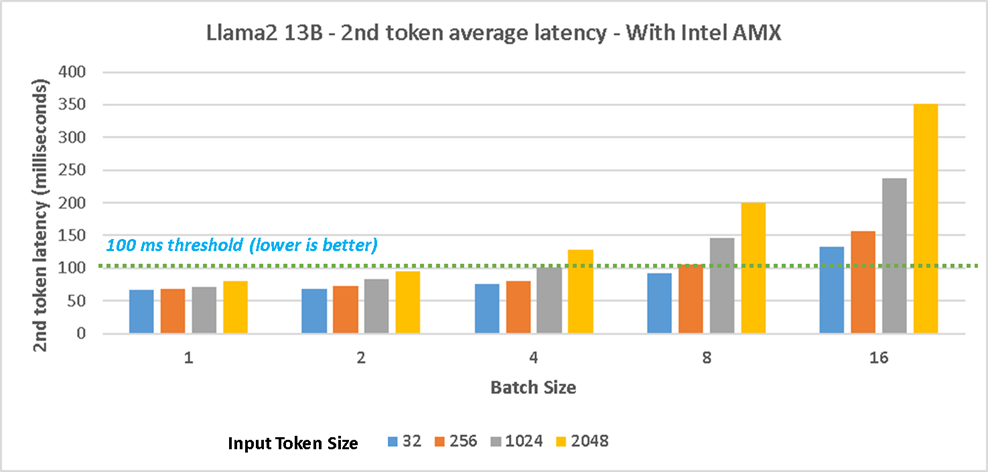
Figure 4. Llama2 13B testing with 4th Gen Intel Xeon CPUs with Intel AMX - 2nd token average latency
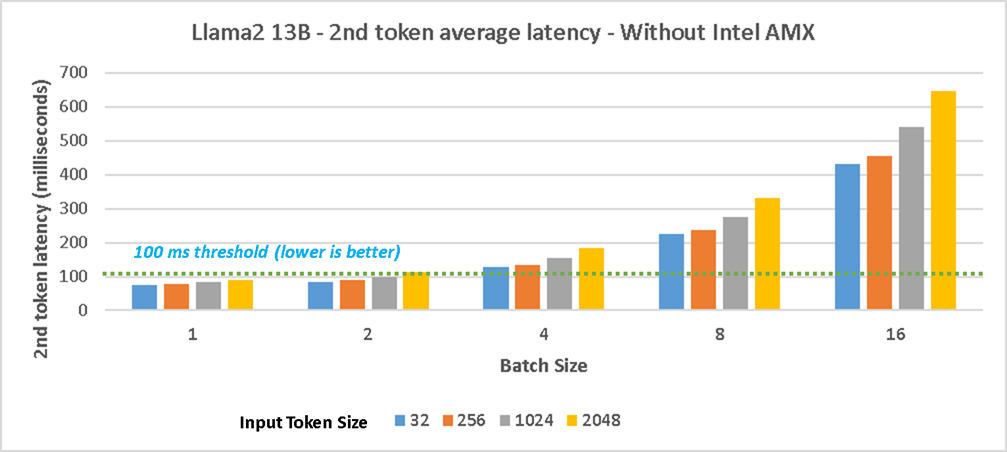
Figure 5. Llama2 13B testing with 4th Gen Intel Xeon CPUs without Intel AMX - 2nd token average latency
LLM Inference Results on vSAN ESA with VMware Cloud Foundation and Tanzu
The Llama2 7B test and inference serving is targeted on single node on a VMware Cloud Foundation(VCF) and Tanzu Kubernetes Cluster running on a 4 Node vSAN ESA cluster with Lenovo ThinkAgile VX650 V3, ESXi 8.0 U3 and one Ubuntu 22.04.4 container. The tests are performed with Intel AMX enabled.
Table 4. Test Configuration
|
Workload |
LLM Inference |
|
Application |
Intel Extension for PyTorch (IPEX) with DeepSpeed |
|
Libraries |
IPEX 2.2 with DeepSpeed 0.13; Pytorch 2.2 (public releases) |
|
Script |
|
|
Test Run settings |
|
|
Model |
Llama2 7B |
|
Dataset |
IPEX.LLM prompt.json (subset of pile-10k) |
|
Batch Size |
1 |
|
Precision |
bfloat16 |
|
Framework |
IPEX 2.2 (public release) |
|
# of Tanzu Containers |
1 |
Table 5 below shows the results for the inference latency and 2nd token average latency performance with Intel AMX on 4th gen Intel Xeon Scalable processors for Llama 7B model.
The scenario tested is with input/output token size 32/256 and the 2nd token latency for batch size 1 is within acceptable threshold of 100 milliseconds and it shows considerable performance increase can be achieved with INT8 quantization. The inference performance on Tanzu containers is comparable with virtual machines performance as shown in Figure 2
Table 5. Llama2 7B testing with 4th Gen Intel Xeon CPUs with Intel AMX and VMware Tanzu
|
Test |
Time (s) |
Inference Latency (ms) |
2nd token Latency (ms) |
|
bfloat16 (input token size =32, output token size=256, batch-szie=1) |
11.47 |
11607 |
45.23 |
|
INT8 (Quantization) (input token size =32, output token size=256, batch-szie=1) |
8.19 |
8187 |
31.79 |
Bill of Materials for ThinkAgile VX650 V3
Accelerated by Intel

To deliver the best experience possible, Lenovo and Intel have optimized this solution to leverage Intel capabilities like processor accelerators not available in other systems. Accelerated by Intel means enhanced performance to help you achieve new innovations and insight that can give your company an edge.
For More Information
To learn more about this Lenovo solution contact your Lenovo Business Partner or visit: https://www.lenovo.com/us/en/servers-storage/solutions/database/
References:
Lenovo ThinkAgile VX650 V3 2U Integrated System and VX650 V3 2U Certified Node
Trademarks
Lenovo and the Lenovo logo are trademarks or registered trademarks of Lenovo in the United States, other countries, or both. A current list of Lenovo trademarks is available on the Web at https://www.lenovo.com/us/en/legal/copytrade/.
The following terms are trademarks of Lenovo in the United States, other countries, or both:
Lenovo®
AnyBay®
ThinkAgile®
ThinkSystem®
XClarity®
The following terms are trademarks of other companies:
Intel®, the Intel logo and Xeon® are trademarks of Intel Corporation or its subsidiaries.
Linux® is the trademark of Linus Torvalds in the U.S. and other countries.
Other company, product, or service names may be trademarks or service marks of others.
Configure and Buy
Please select a locale
Full Change History
Course Detail
Employees Only Content
The content in this document with a is only visible to employees who are logged in. Logon using your Lenovo ITcode and password via Lenovo single-signon (SSO).
The author of the document has determined that this content is classified as Lenovo Internal and should not be normally be made available to people who are not employees or contractors. This includes partners, customers, and competitors. The reasons may vary and you should reach out to the authors of the document for clarification, if needed. Be cautious about sharing this content with others as it may contain sensitive information.
Any visitor to the Lenovo Press web site who is not logged on will not be able to see this employee-only content. This content is excluded from search engine indexes and will not appear in any search results.
For all users, including logged-in employees, this employee-only content does not appear in the PDF version of this document.
This functionality is cookie based. The web site will normally remember your login state between browser sessions, however, if you clear cookies at the end of a session or work in an Incognito/Private browser window, then you will need to log in each time.
If you have any questions about this feature of the Lenovo Press web, please email David Watts at dwatts@lenovo.com.





