

Top
Updated
28 Feb 2024Form Number
LP1902PDF size
9 pages, 898 KBSubscribed to LP1902.
Thank you for your feedback.
Abstract
It’s no longer a matter of whether enterprises should start utilizing Generative AI in their business, but rather, how to do it. Learn how Lenovo and Intel have created a cost-effective Generative AI solution that is easy to deploy and scale, helping companies achieve revolutionary business impacts more quickly.
This solution brief highlights a multi-node solution with Red Hat OpenShift, expanding upon an earlier solution brief that highlighted a single node solution.
Simplified Deployment, Scalability, and Management
Getting started with Generative AI can seem complicated, but the good news is that companies don’t have to start from scratch. They can extend their existing infrastructure with the Lenovo ThinkSystem SR650 V3, accelerated by 5th Gen Intel® Xeon® processors, and achieve powerful business impacts without having to invest in dedicated (and often costly) GPU accelerators. Deploying Generative AI use-cases on a cluster with Red Hat® OpenShift® container platform allows for ease of deployment, usability, and scalability with containers and services managed by Kubernetes. Red Hat OpenShift makes the most of Lenovo’s AI optimized hardware, since it supports hardware acceleration for inference use cases, a broad ecosystem of AI/ML and application development tools, and integrated security and operations management capabilities. AI models can be updated frequently to improve accuracy by integrated DevOps capabilities in OpenShift.
Solution and Testing Overview
Testing has shown the Lenovo ThinkSystem SR650 V3, with 5th Gen Intel Xeon processors, delivers a highly performant, scalable solution for Generative AI. A next token latency of 100ms or less is a response time perceived as instantaneous for most conversational AI and text summarization applications. Test results demonstrated this solution could successfully meet that target and provide the necessary performance to support a variety of use cases, including real-time chatbots.
The Lenovo ThinkSystem SR650 V3 offers high performance, storage, and memory capacity to tackle complex workloads that require optimized hardware architecture - like Generative AI. With flexible storage and networking options, the SR650 V3 can easily scale for changing needs. The ThinkSystem SR650 V3 supports one or two 5th Gen Intel Xeon processors. With built-in Intel® Advanced Matrix Extensions (AMX), 5th Gen Intel Xeon processors deliver high performance on cutting-edge AI models.
Enterprises may require multiple Generative AI models to perform different tasks, including image creation, synthetic data generation, and chatbots. Generative AI models can require a large amount of storage. The ThinkSystem SR650 V3 can support many Generative AI models in a single 2U server with its tremendous amount of storage and flexibility. With three drive bay zones, it supports up to 20x 3.5-inch or 40x 2.5-inch hotswap drive bays.
The ThinkSystem SR650 V3 offers energy-efficiency features to save energy and reduce operational costs for Generative AI workloads. These features include advanced direct-water cooling (DWC) with the Lenovo Neptune Processor DWC Module, where heat from the processors is removed from the rack and data center using an open loop and coolant distribution units, resulting in lower energy costs, high-efficiency power supplies with 80 PLUS Platinum and Titanium certifications, and optional Lenovo XClarity Energy Manager, which provides advanced data center power notification, analysis, and policy-based management to help achieve lower heat output and reduced cooling needs.

Figure 1. Lenovo ThinkSystem SR650 V3
Results
The Generative AI testing on up to 4x Lenovo ThinkSystem SR650 V3 servers with 5th Gen Intel Xeon processors was performed by Intel and validated by Lenovo. The setup involves an 8-node cluster which includes 3x control plane nodes and 4x worker nodes powered by Red Hat OpenShift. Red Hat OpenShift is an industry leading hybrid cloud application platform powered by Kubernetes. Using Red Hat OpenShift, Lenovo and Intel showcases a platform for deploying, running, and managing applications with ease-of-use and scalability in mind. Red Hat OpenShift delivers a consistent experience across public cloud, on-premises, hybrid cloud, or edge architecture.
A variety of batch sizes were used to simulate concurrent users and input token lengths between 256-2048 represent a typical enterprise chatbot scenario. The workloads chosen for these tests were the Llama 2 model and the Falcon model, both of which are available from HuggingFace. The software stack and model-specific parameters are documented in Table 2 below.
Based on our initial profiling of the workloads, we chose ‘network-latency’ as the system setting profile. As mentioned in Red Hat Enterprise Linux Performance Tuning Guide documentation, the network-latency profile optimizes for low latency network tuning. It is based on the latency-performance profile. It additionally disables transparent hugepages, NUMA balancing and tunes several other network related sysctl parameters. Figure 2 below shows for LLAMA 2 13B parameters, 1x Lenovo ThinkSystem SR650 V3 with 5th Gen Intel Xeon processors helps achieve less than 100ms next token latency from batch size 1 to batch size 8 for Generative AI inference across input token lengths 256 to 1024.
As demonstrated below with Falcon 40B parameters, given the model size and architecture, 4x Lenovo ThinkSystem SR650 V3 with 5th Gen Intel Xeon processors helps achieve less than 100ms next token latency from batch size 1 to batch size 4 for Generative AI inference across input token lengths 256 to 2048.
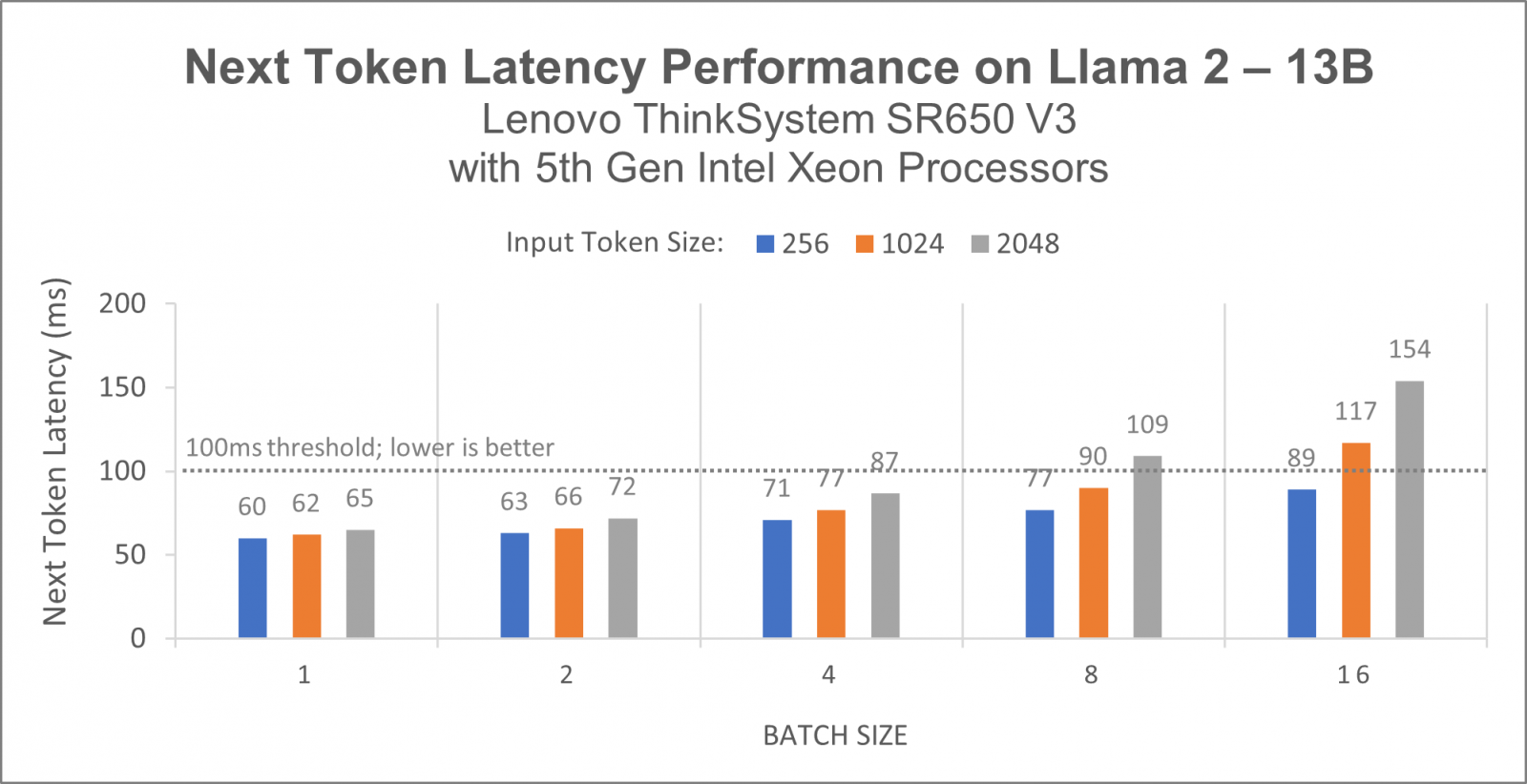
Figure 2. Llama 2-13B performance with BF16 precision on Lenovo ThinkSystem SR650 V3 on 1 node with 2x 5th Gen Intel Xeon CPU using DeepSpeed (AutoTP)

Figure 3. Falcon-40B performance with BF16 precision on 4x Lenovo ThinkSystem SR650 V3 with 2x 5th Gen Intel Xeon CPU using DeepSpeed (AutoTP)
Configuration Details
Tested by Intel as of January 2024
Conclusion
Lenovo offers AI optimized infrastructure, including the SR650 V3, for energy-efficient, high-performance computing to address large language models and any other AI workload challenge. To see this and other Lenovo AI solutions, please visit https://www.lenovo.com/ai
For customers looking to adopt AI faster, Lenovo's AI Discover Center of Excellence (COE) provides access to AI experts, workshops, and best practices. We can help you develop optimized solutions that enable you to extract valuable business insights from your data quickly, responsibly, and ethically. Contact the AI Discover COE directly here.
Accelerated by Intel
To deliver the best experience possible, Lenovo and Intel have optimized this solution to leverage Intel capabilities like processor accelerators not available in other systems. Accelerated by Intel means enhanced performance to help you achieve new innovations and insight that can give your company an edge.

Why Lenovo
Lenovo is a US$70 billion revenue Fortune Global 500 company serving customers in 180 markets around the world. Focused on a bold vision to deliver smarter technology for all, we are developing world-changing technologies that power (through devices and infrastructure) and empower (through solutions, services and software) millions of customers every day.
For More Information
To learn more about this Lenovo solution contact your Lenovo Business Partner or visit: https://www.lenovo.com/ai
Trademarks
Lenovo and the Lenovo logo are trademarks or registered trademarks of Lenovo in the United States, other countries, or both. A current list of Lenovo trademarks is available on the Web at https://www.lenovo.com/us/en/legal/copytrade/.
The following terms are trademarks of Lenovo in the United States, other countries, or both:
Lenovo®
Neptune®
ThinkSystem®
XClarity®
The following terms are trademarks of other companies:
Intel®, the Intel logo and Xeon® are trademarks of Intel Corporation or its subsidiaries.
Linux® is the trademark of Linus Torvalds in the U.S. and other countries.
Other company, product, or service names may be trademarks or service marks of others.
Configure and Buy
Please select a locale
Full Change History
Course Detail
Employees Only Content
The content in this document with a is only visible to employees who are logged in. Logon using your Lenovo ITcode and password via Lenovo single-signon (SSO).
The author of the document has determined that this content is classified as Lenovo Internal and should not be normally be made available to people who are not employees or contractors. This includes partners, customers, and competitors. The reasons may vary and you should reach out to the authors of the document for clarification, if needed. Be cautious about sharing this content with others as it may contain sensitive information.
Any visitor to the Lenovo Press web site who is not logged on will not be able to see this employee-only content. This content is excluded from search engine indexes and will not appear in any search results.
For all users, including logged-in employees, this employee-only content does not appear in the PDF version of this document.
This functionality is cookie based. The web site will normally remember your login state between browser sessions, however, if you clear cookies at the end of a session or work in an Incognito/Private browser window, then you will need to log in each time.
If you have any questions about this feature of the Lenovo Press web, please email David Watts at dwatts@lenovo.com.





