

Top
Author
Published
27 Nov 2024Form Number
LP2067PDF size
11 pages, 334 KBSubscribed to LP2067.
Thank you for your feedback.
Abstract
4th Gen and 5th Gen Intel Xeon Scalable processors include the built-in AI acceleration engine, Intel Advanced Matrix Extensions (Intel AMX) which accelerates artificial intelligence and machine learning workloads. In this paper, we introduce the Intel AMX accelerator and how to enable them with VMware ESXi 8.0 U3 and a Ubuntu server 24.04.1 virtual machine.
This paper is for technical specialists who are looking to deploy the accelerator. The paper assumes the reader is familiar with x86 instruction set and VMware vSphere products.
Introduction
Artificial Intelligence is transforming how we work and live every day, and it is evolving rapidly, continues to make groundbreaking advancements, drawing interest from business, research and consumer. Business can benefit from applying AI in various scenarios, that range from image processing, recommendation systems, natural language processing and machine learning.
At its essence, AI is the process of converting raw data into actionable insights. The typical AI workflow occurs in three stages: data engineering, AI training, and inference. Each stage has different memory, compute, and latency requirements. GPUs were originally designed for rendering graphics but have become crucial for AI due to their ability to handle parallel processing tasks efficiently. However the latest GPUs are more expensive and hard-to-procure, organizations need significantly more processing power to increase the performance of AI/ML workloads.
The 4th generation and the 5th generation Intel Xeon Scalable Processors are the unique, scalable platform optimized for different workloads accelerations including HPC, AI, BigData, Networking etc, with higher performance and lower total cost of ownership. The new built-in AI acceleration engine Intel Advanced Matrix Extensions (Intel AMX), are extensions to the x86 instruction set architecture for microprocessors from Intel designed to work on matrices to accelerate AI and machine learning workloads.
The AMX supports 16-bit brain floating point (BF16) and 8-bit integer (INT8) data types of low-precision matrix operations to boost the instructions per cycle for AI applications. With the high-speed matrix multiplication enabled by Intel AMX, the Intel Xeon Scalable processor can quickly pivot between optimizing general computing and AI workloads.
Intel AMX introduces the new extensions to the x86 Instruction Set Architecture (ISA) to work on matrices and which accelerate matrix multiplication in AI workloads.
Intel AMX consists of two components as the Figure 1 shows:
- A set of 2-dimensional registers (tiles) representing sub-arrays from a larger 2-dimensional memory image
- An accelerator able to operate on tiles
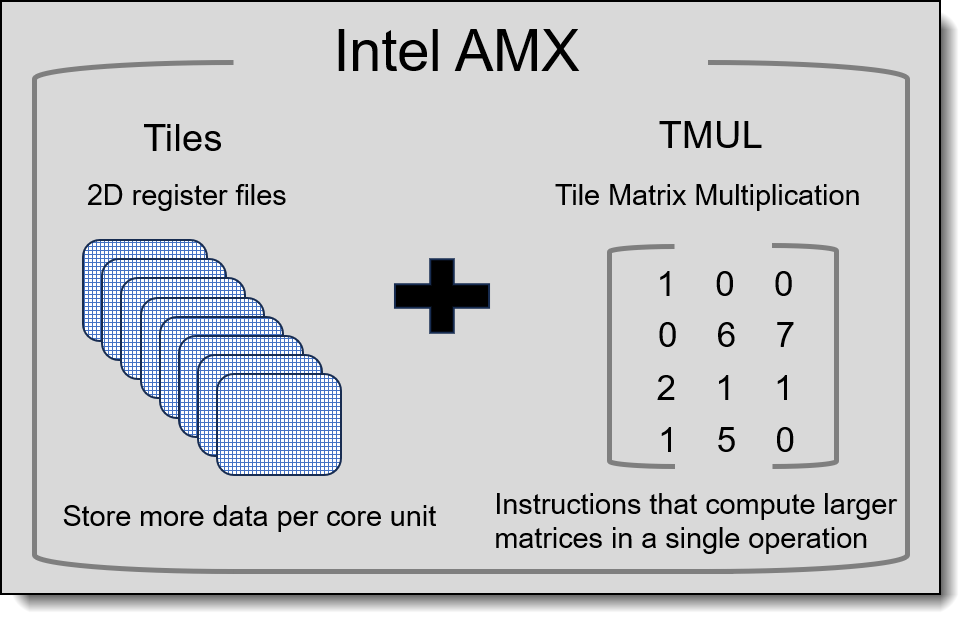
Intel AMX will store larger chunks of data in each core and then compute larger matrices in a single operation. The first implementation is called TMUL (tile matrix multiply unit) that comprises a grid of fused multiply-add units capable of operating on tiles. In its initial form, it implements a set of up to eight tiles (named TMM0 … TMM7), which are arrays with 16 rows of size of 64 bytes. Load a tile representing a small section from a larger image in memory, operate on that tile, and repeat with the next tile that represents the next portion of the image. When done, store the resultant tile to memory.
Figure 2 shows a conceptual diagram of the Intel AMX architecture. The Intel architecture host drives the algorithm, the memory blocking, loop indices and pointer arithmetic. Intel AMX instructions are synchronous in the Intel architecture instruction stream and the memory loaded and stored by the tile instruction is coherent with respect to the host’s memory accesses.
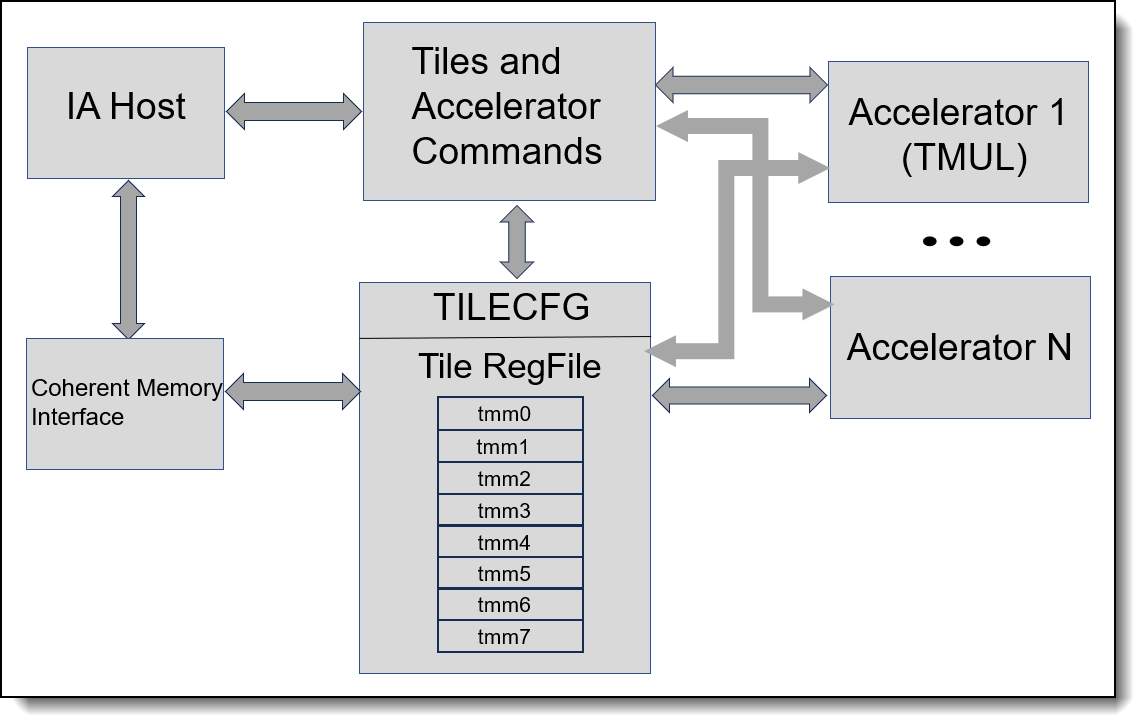
Figure 2. Intel AMX architecture
The AMX introduces 12 new instructions and comprises of three sub-extensions:
- AMX-TILE
- AMX-INT8
- AMX-BF16
The 12 instructions are listed in the following table.
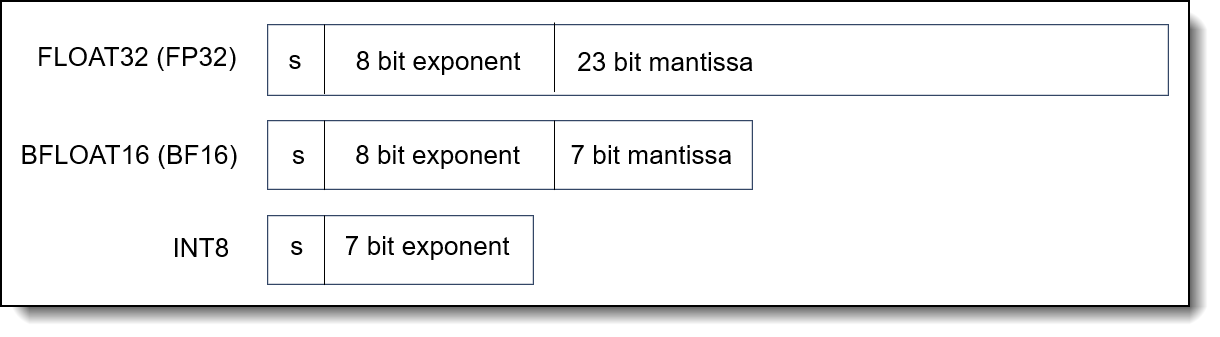
The default floating point precision of a CPU primitive is single-precision floating point (float 32 or FP32). FP32 is a standard 32-bit floating-point data type used to train deep learning models and for inferencing. This data type is more computationally demanding than other data types but typically achieves high accuracies.
By reducing the size of data during computation will achieve better performance. Intel AMX supports BF16 and INT8 data types, augmenting the optimizations from Intel AVX512 and Intel deep learning boost to enable fast and efficient AI and deep learning across various industries and use cases. BF16 is a truncated version of FP32 used for training and inference, and it offers similar accuracy but faster computation. INT8 offers higher performance and is the least computationally demanding data type, ideal for real-time application and matrix multiplication tasks where speed and efficiency are a priority. It has the minimal impact on accuracy. The comparison of different data types is shown in Figure 3.
Test configuration
The test bed configuration of ThinkSystem ST650 V3 is listed in the following table. Intel AMX instructions are supported on ESXi 8.0 U1 and above with VMs using virtual HW version 20 and above. The guest OS running Linux should use kernel version 5.16 or later. Kernel version 5.19 or later is recommended.
Implementing Intel AMX
This section describes the steps we took to configure and use Intel AMX in VMware ESXi 8.0 Update 3.
The steps to implement Intel AMX are as follows:
- Power on the server and install VMware ESXi 8.0U3
- Connect to the vCenter Server 8.0U3 by using the vSphere Client and add the host to the data center.
- Create a virtual machine and install a guest OS (e.g., Ubuntu server 24.04.1) with kernel version 5.19 or later.
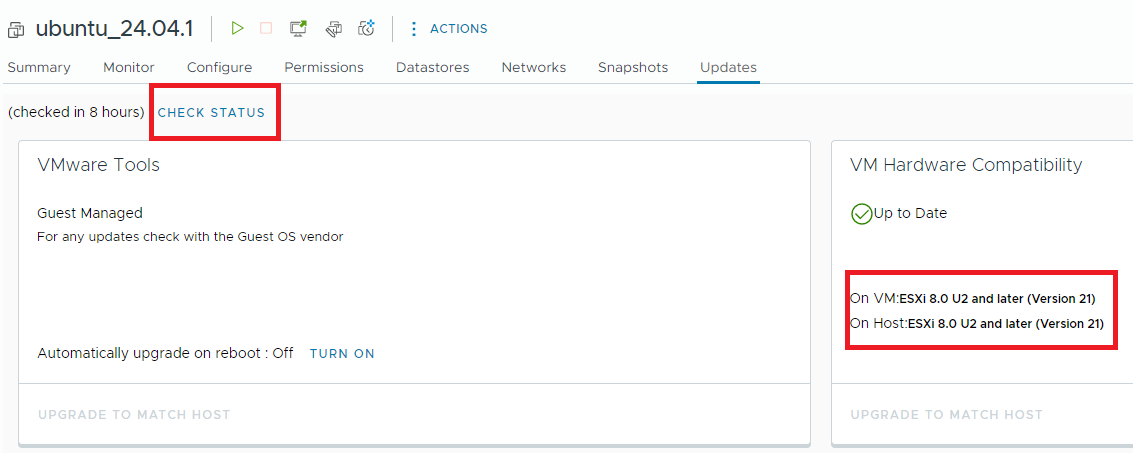
- Find out the virtual HW version a VM is using by one of the two ways:
- In the vCenter Server, go to the Updates tab of the VM, and click the CHECK STATUS button, the result is displayed at the right-hand side, as figure 4 shows, the virtual HW version is 21.
- The other way is Check VMware products and virtual HW version on Broadcom web:
https://knowledge.broadcom.com/external/article?articleNumber=315655
- Login to the guest VM, use the following command on the terminal and search for AMX in the flags section, and make sure the AMX flags (amx_bf16, amx_tile and amx_int8) are supported by the CPU.
~# cat /proc/cpuinfo | grep -i amx

Figure 5. AMX Flags from CPU InfoWe can also use cpuid command to dump CPUID information and ensure that the VM can access the hardware’s AMX instructions.
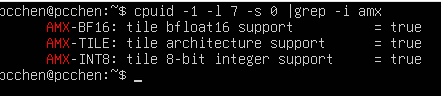
~# cupid -1 -l 7 -s 0 | grep -i amx
Intel provides a sample code to demonstrate testing the new instructions using intrinsic function. The test code will multiply matrices A and B of size 16x64 containing INT8 value and accumulate the result to a 16x16 matrix C containing INT32 value. It’s simplified to highlight use of Intel AMX instruction to configure the tiles, load data from memory into tiles, perform INT8 matrix multiplication on tile data and copy the result from tiles to memory. We will explain some code snippets below.
- Declare the tile config data structure that will hold the control register for tile configuration and format defined as a 64-byte memory location.
typedef struct __tile_config { uint8_t palette_id; uint8_t start_row; uint8_t reserved_0[14]; uint16_t colsb[16]; uint8_t rows[16]; } __tilecfg;Figure 7. Struct Tile Config Declaration
- Initialize the tile config variable with the specific information given by the matrices and the _tile_loadconfig() intrinsic function is used to load the tile configuration metadata from the 64-byte memory location specified by tileinfo.
static void init_tile_config (__tilecfg *tileinfo) { int i; tileinfo->palette_id = 1; tileinfo->start_row = 0; for (i = 0; i < 1; ++i) { tileinfo->colsb[i] = MAX_ROWS; tileinfo->rows[i] = MAX_ROWS; } for (i = 1; i < 4; ++i) { tileinfo->colsb[i] = MAX_COLS; tileinfo->rows[i] = MAX_ROWS; } _tile_loadconfig (tileinfo); }Figure 8. Tile Config Variable Initialization
- The application will need to invoke a system call to request access to Intel AMX feature. This is performed using the arch_prctl() command (ARCH_REQ_XCOMP_PERM) to request permission to use Intel AMX and can require XSTATE component to be enabled. Intel AMX is an XSAVE-enabled feature, meaning that it requires use of the XSAVE feature set for their enabling.
static bool set_tiledata_use() { if (syscall(SYS_arch_prctl, ARCH_REQ_XCOMP_PERM, XFEATURE_XTILEDATA)) { printf("\n Fail to do XFEATURE_XTILEDATA \n\n"); return false; } else { printf("\n TILE DATA USE SET - OK \n\n"); return true; } return true; }Figure 9. Application Request to Access to Intel AMX
- The _tile_loadd() intrinsic function can be used to load tiles from memory specified by base address (src1, src2 and res), and the _tile_dpbssd() function can be used to compute dot-product of bytes in tiles with a source/destination accumulator. Lastly, the _tile_stored() function stores the result of the matrix multiplication operation to memory specified by res address.
// Load tile rows from memory _tile_loadd (2, src1, STRIDE); _tile_loadd (3, src2, STRIDE); _tile_loadd (1, res, STRIDE); // Compute dot-product of bytes in tiles _tile_dpbssd (1, 2, 3); // Store the tile data to memory _tile_stored (1, res, STRIDE);Figure 10. Tile Intrinsic Functions
The result of the sample code is showed in below Figure 10. The full sample code is available on the website and it’s for demonstration purpose only.

Summary
As part of Intel AI Engines, Intel AMX was designed to balance inference, the prominent use case for a CPU in AI applications, with more capabilities for training. Selecting the Intel Xeon processors with Intel AMX for new AI deployment is an efficient and cost-effective approach to accelerating AI workloads.
VMware announced a collaboration with Intel to help customers accelerate the adoption of AI and enable private AI everywhere – across data centers, public could and edge environments, develop and deploy classical machine learning models and generative AI applications on the infrastructure with built-in AI acceleration and managed by VMware Cloud Foundation.
The Intel AI software suite and VMware Cloud Foundation are validated on Lenovo ThinkSystem and ThinkAgile servers with 4th and 5th Gen Intel Xeon Scalable processors. For more information, see the Solution Brief, VMware Private AI with Intel on Lenovo ThinkAgile VX V3 and ThinkSystem V3.
Reference
For more information, see these resources:
- Intel Advanced Matrix Extensions Overview
https://www.intel.com/content/www/us/en/products/docs/accelerator-engines/advanced-matrix-extensions/overview.html - Developer Resources from Intel and VMware by Broadcom
https://www.intel.com/content/www/us/en/developer/ecosystem/vmware.html - Intel Intrinsics Guide
https://www.intel.com/content/www/us/en/docs/intrinsics-guide/index.html - AMX Sample code
https://github.com/intel/AMX-TMUL-Code-Samples/tree/main
Author
Alpus Chen is an OS Engineer at the Lenovo Infrastructure Solutions Group in Taipei, Taiwan. As a specialist in Linux and VMware technical support for several years, he is interested in operating system operation and recently focuses on VMware OS.
Thanks to the following specialists for their contributions and suggestions:
- Skyler Zhang, Lenovo VMware Engineer
- Gary Cudak, Lenovo OS Architect
- David Watts, Lenovo Press
Trademarks
Lenovo and the Lenovo logo are trademarks or registered trademarks of Lenovo in the United States, other countries, or both. A current list of Lenovo trademarks is available on the Web at https://www.lenovo.com/us/en/legal/copytrade/.
The following terms are trademarks of Lenovo in the United States, other countries, or both:
Lenovo®
ThinkAgile®
ThinkSystem®
The following terms are trademarks of other companies:
Intel®, the Intel logo and Xeon® are trademarks of Intel Corporation or its subsidiaries.
Linux® is the trademark of Linus Torvalds in the U.S. and other countries.
Other company, product, or service names may be trademarks or service marks of others.
Configure and Buy
Please select a locale
Full Change History
Course Detail
Employees Only Content
The content in this document with a is only visible to employees who are logged in. Logon using your Lenovo ITcode and password via Lenovo single-signon (SSO).
The author of the document has determined that this content is classified as Lenovo Internal and should not be normally be made available to people who are not employees or contractors. This includes partners, customers, and competitors. The reasons may vary and you should reach out to the authors of the document for clarification, if needed. Be cautious about sharing this content with others as it may contain sensitive information.
Any visitor to the Lenovo Press web site who is not logged on will not be able to see this employee-only content. This content is excluded from search engine indexes and will not appear in any search results.
For all users, including logged-in employees, this employee-only content does not appear in the PDF version of this document.
This functionality is cookie based. The web site will normally remember your login state between browser sessions, however, if you clear cookies at the end of a session or work in an Incognito/Private browser window, then you will need to log in each time.
If you have any questions about this feature of the Lenovo Press web, please email David Watts at dwatts@lenovo.com.





