

Top
Published
17 Jun 2025Form Number
LP2236PDF size
34 pages, 3.6 MBSubscribed to LP2236.
Thank you for your feedback.
Table of Contents
Abstract
This document is meant to be used in tandem with the Hybrid AI 285 platform guide. It describes the hardware architecture changes required to leverage Cisco networking hardware and the Cisco Nexus Dashboard within the Hybrid AI 285 Platform.
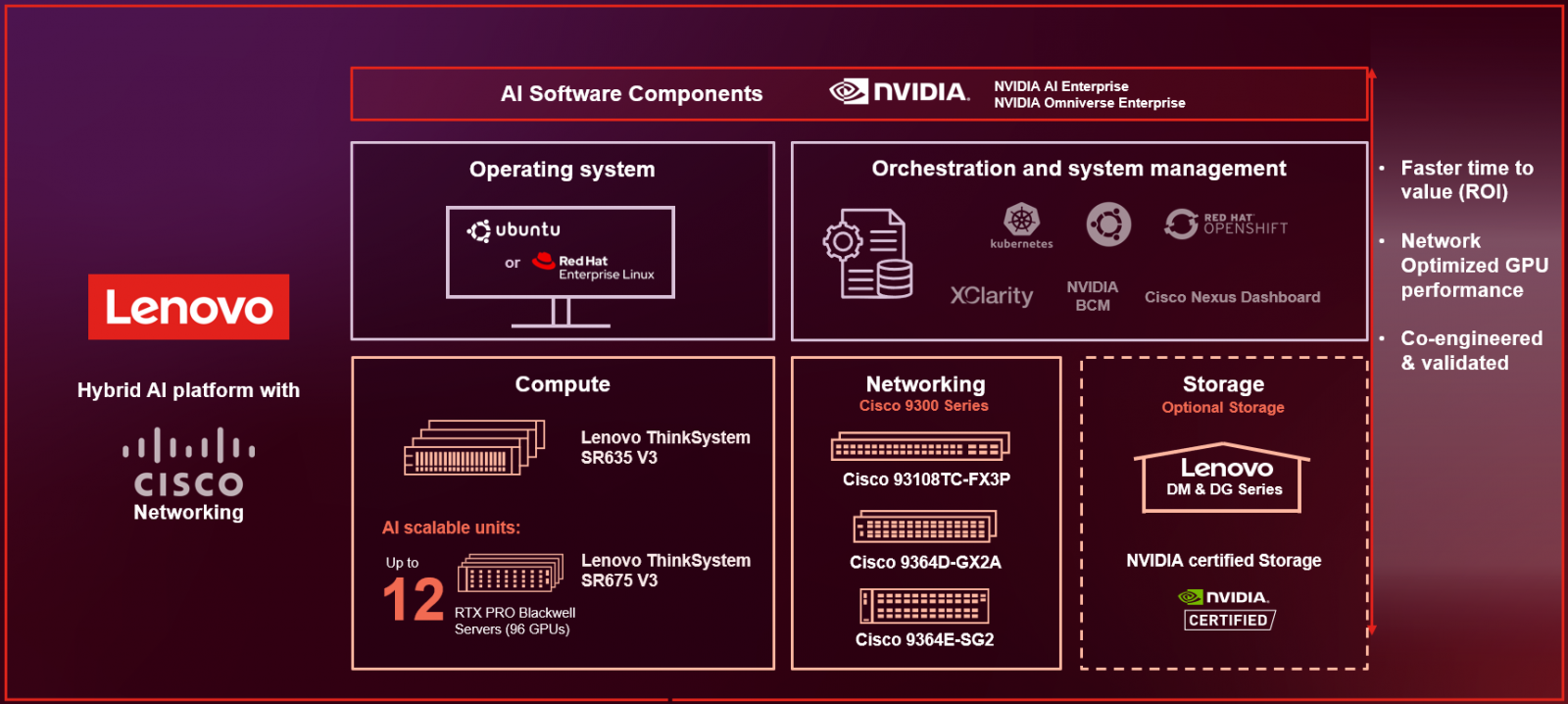
Lenovo Hybrid AI 285 is a platform that enables enterprises of all sizes to quickly deploy hybrid AI factory infrastructure, supporting Enterprise AI use cases as either a new, greenfield environment or an extension of their existing IT infrastructure. This document will often send the user to the base Hybrid AI 285 platform guide as its main purpose is to show the main differences required to implement Cisco networking and Nexus dashboard.
This guide is for sales architects, customers and partners who want to quickly stand up a validated AI infrastructure solution.
Introduction
This document is meant to be used in tandem with the Hybrid AI 285 platform guide. It describes the hardware architecture changes required to leverage Cisco networking hardware and the Cisco Nexus Dashboard within the Hybrid AI 285 Platform.
Lenovo Hybrid AI 285 is a platform that enables enterprises of all sizes to quickly deploy hybrid AI factory infrastructure, supporting Enterprise AI use cases as either a new, greenfield environment or an extension of their existing IT infrastructure. This document will often send the user to the base Hybrid AI 285 platform guide as its main purpose is to show the main differences required to implement Cisco networking and Nexus dashboard.
The offering is based on the NVIDIA 2-8-5 PCIe-optimized configuration — 2x CPUs, 8x GPUs, and 5x network adapters — and is ideally suited for medium (per GPU) to large (per node) Inference use cases, and small-to-large model training or fine-tuning, depending on chosen scale. It combines market leading Lenovo ThinkSystem GPU-rich servers with NVIDIA Hopper or Blackwell GPUs, Cisco networking and enables the use of the NVIDIA AI Enterprise software stack with NVIDIA Blueprints.
Did you know?
The same team of HPC and AI experts that created the Lenovo EveryScale OVX solution, as deployed for NVIDIA Omniverse Cloud, brings the Lenovo Hybrid AI 285 with Cisco networkingto market.
Following their excellent experience with Lenovo on Omniverse, NVIDIA has once again chosen Lenovo technology as the foundation for the development and test of their NVIDIA AI Enterprise Reference Architecture (ERA).
Overview
The Lenovo Hybrid AI 285 Platform with Cisco Networking scales from a Starter Kit environment with between 4-32 PCIe GPUs to a Scalable Unit Deployment (SU) with four servers and 32 GPUs in each SU and up to 3 Scalable Units with 12 Servers and 96 GPUs. See figure below for a sizing overview.
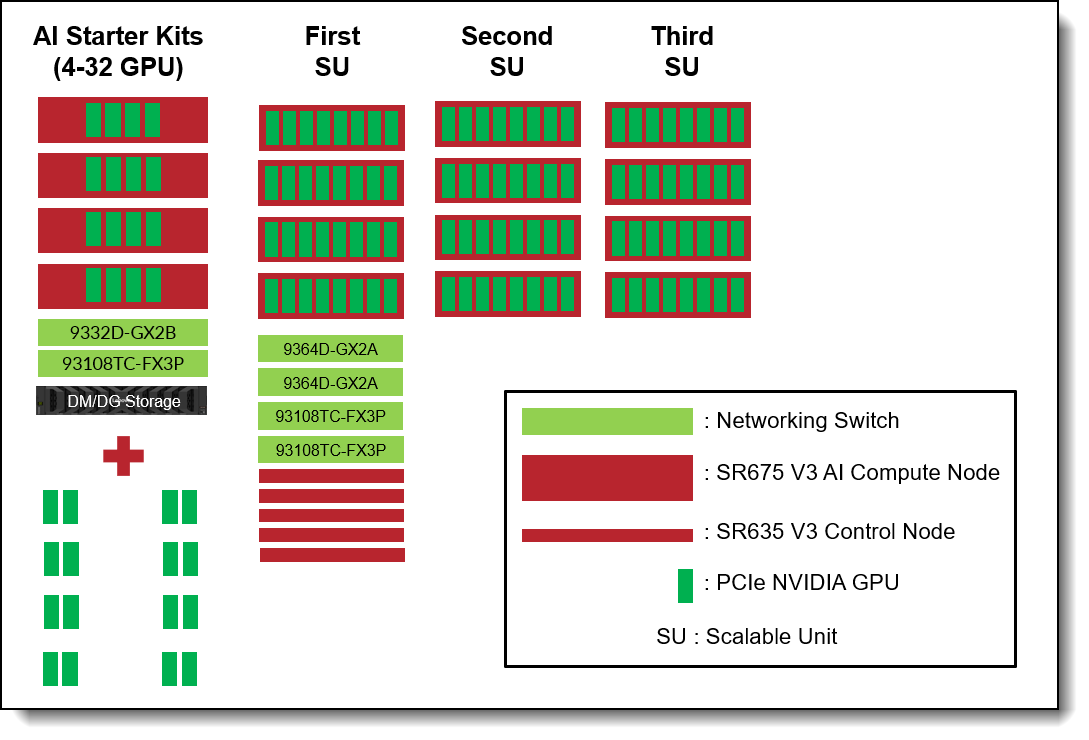
Figure 2. Lenovo Hybrid AI 285 with Cisco Networking scaling from Starter Kit to 96 GPUs
The figure below shows the networking architecture of the platform deployed with 96 GPUs.
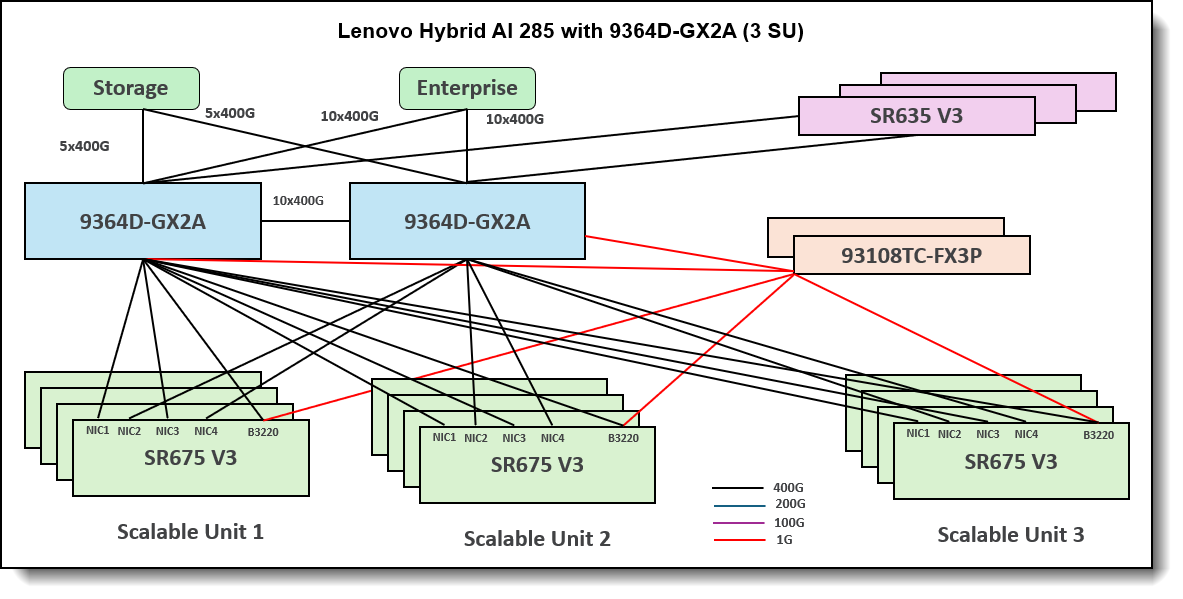
Figure 3. Lenovo Hybrid AI 285 with Cisco Networking platform with 3 Scalable Units
Components
The main hardware components of Lenovo Hybrid AI platforms are Compute nodes and the Networking infrastructure. As an integrated solution they can come together in either a Lenovo EveryScale Rack (Machine Type 1410) or Lenovo EveryScale Client Site Integration Kit (Machine Type 7X74).
Topics in this section:
AI Compute Node – SR675 V3
The AI Compute Node leverages the Lenovo ThinkSystem SR675 V3 GPU-rich server.

Figure 4. Lenovo ThinkSystem SR675 V3 in 8DW PCIe Setup
The SR675 V3 is a 2-socket 5th Gen AMD EPYC 9005 server supporting up to 8 PCIe DW GPUs with up to 5 network adapters in a 3U rack server chassis. This makes it the ideal choice for NVIDIA’s 2-8-5 configuration requirement.

Figure 5. Lenovo ThinkSystem SR675 V3 in 8DW PCIe Setup
The SR675 V3 is configured as the 285 AI compute node as shown in the figure below.
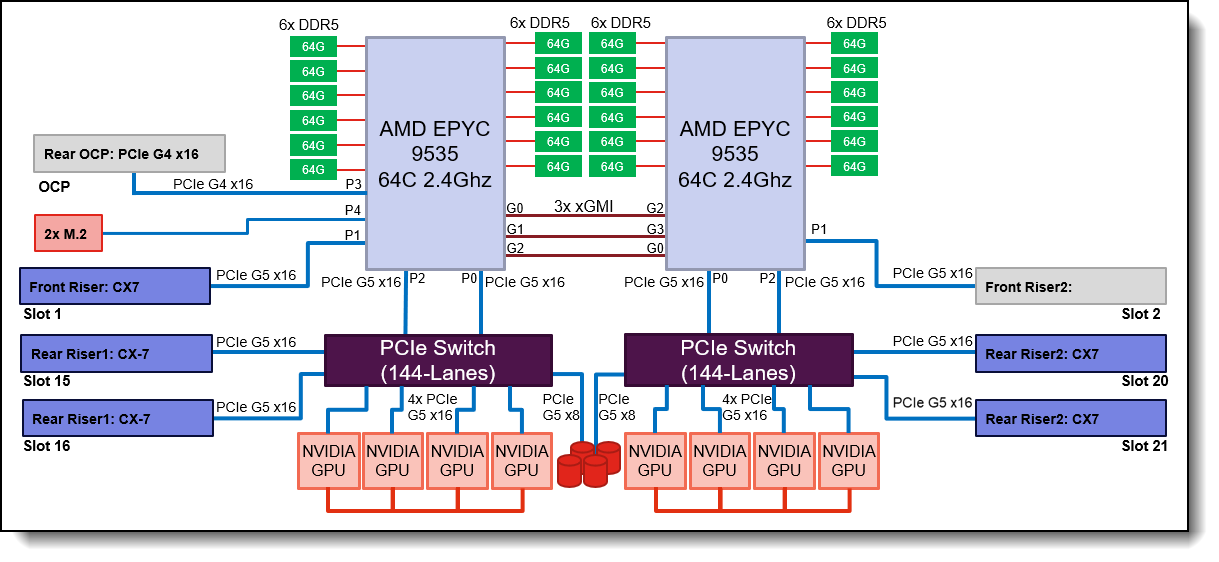
Figure 6. AI Compute Node Block Diagram
The AI Compute node is configured with two AMD EPYC 9535 64 Core 2.4 GHz processors with an all-core boost frequency of 3.5GHz. Besides providing consistently more than 2GHz frequency this ensures that with 7 Multi Instance GPUs (MIG) on 8 physical GPUs there are 2 Cores available per MIG plus a few additional Cores for Operating System and other operations.
With 12 memory channels per processor socket the AMD based server provides superior memory bandwidth versus competing Intel-based platforms ensuring highest performance. Leveraging 64GB 6400MHz Memory DIMMs for a total of 1.5TB of main memory providing 192GB memory per GPU or a minimum of 1.5X the H200 NVL GPU memory.
The GPUs are connected to the CPUs via two PCIe Gen5 switches, each supporting up to four GPUs. With the NVIDIA H200 NVL PCIe GPU, the four GPUs are additionally interconnected through an NVLink bridge, creating a unified memory space. In an entry configuration with two GPUs per PCIe switch, the ThinkSystem SR675 V3 uniquely supports connecting all four GPUs with an NVLink bridge for maximized shared memory, thereby accommodating larger inference models, rather than limiting the bridge to two GPUs. With the RTX PRO 6000 Blackwell Server Edition, no NVLink bridge is applicable, same applies to configurations with the L40S.
Key difference from the base platform: For the 2-8-5 architecture with Cisco networking the AI Compute node leverages NVIDIA CX-7s for both the East-West and the North South communication. This is a key difference in the AI compute node configuration compared to the base 285 platform with NVIDIA networking. This is done primarily because, as of now, Cisco switching does not work with NVIDIA’s dynamic load balancing technology within Spectrum-X, leveraged by their Bluefield-3 cards. This will change in future updates of this document as that technology is onboarded by Cisco and Lenovo brings in the new Silicon One 800GbE switch.
The Ethernet adapters for the Compute (East-West) Network are directly connected to the GPUs via PCIe switches minimizing latency and enabling NVIDIA GPUDirect and GPUDirect Storage operation. For pure Inference workload they are optional, but for training and fine-tuning operation they should provide at least 200Gb/s per GPU.
Finally, the system is completed by local storage with two 960GB Read Intensive M.2 in RAID1 configuration for the operating system and four 3.84TB Read Intensive E3.S drives for local application data.
GPU selection
The Hybrid AI 285 platform is designed to handle any of NVIDIA’s DW PCIe form factor GPUs including the new RTX PRO 6000 Blackwell Server Edition, the H200 NVL, L40S and the H100 NVL.
- NVIDIA H200 NVL
The NVIDIA H200 NVL is a powerful GPU designed to accelerate both generative AI and high-performance computing (HPC) workloads. It boasts a massive 141GB of HBM3e memory, which is nearly double the capacity of its predecessor, the H100. This increased memory, coupled with a 4.8 terabytes per second (TB/s) memory bandwidth, enables the H200 NVL to handle larger and more complex AI models, like large language models (LLMs), with significantly improved performance. In addition, the H200 NVL is built with energy efficiency in mind, offering increased performance within a similar power profile as the H100, making it a cost-effective and environmentally conscious choice for businesses and researchers.
NVIDIA provides a 5-year license to NVIDIA AI Enterprise free-of-charge bundled with NVIDIA H200 NVL GPUs.
- NVIDIA RTX PRO 6000 Blackwell Server Edition
Built on the groundbreaking NVIDIA Blackwell architecture, the NVIDIA RTX PRO™ 6000 Blackwell Server Edition delivers a powerful combination of AI and visual computing capabilities to accelerate enterprise data center workloads. Equipped with 96GB of ultra- fast GDDR7 memory, the NVIDIA RTX PRO 6000 Blackwell provides unparalleled performance and flexibility to accelerate a broad range of use cases- from agentic AI, physical AI, and scientific computing to rendering, 3D graphics, and video.
Configuration
The following table lists the configuration of the AI Compute Node with H200 NVL GPUs.
Service Nodes – SR635 V3
When deploying the Hybrid AI 285 platform in a sizing beyond beyond 2 AI compute nodes additional service nodes are recommended to manage the overall AI cluster environment.
Key difference from the base platform: Because the architecture for this platform does not yet leverage Spectrum-X, there is no need for Bluefields within the service nodes. For this reason the customer can leverage the lower cost SR635 V3 instead of the SR655 V3.
Two Management Nodes provide a high-availability for the System Management and Monitoring provided through NVIDIA Base Command Manager (BMC) as described further in the AI Software Stack chapter.
For the Container operations three Scheduling Nodes build the Kubernetes control plane providing redundant operations and quorum capability.

Figure 7. Lenovo ThinkSystem SR635 V3
The Lenovo ThinkSystem SR635 V3 is an optimal choice for a homogeneous host environment, featuring a single socket AMD EPYC 9335 with 32 cores operating at 3.0 GHz base with an all-core boost frequency of 4.0GHz. The system is fully equipped with twelve 32GB 6400MHz Memory DIMMs, two 960GB Read Intensive M.2 drives in RAID1 configuration for the operating system, and two 3.84TB Read Intensive U.2 drives for local data storage. Additionally, it includes a NVIDIA dual port CX7 adapter to connect the Service Nodes to the Converged Network.
Configuration
The following table lists the configuration of the Service Nodes.
Cisco Networking
The default setup of the Lenovo Hybrid AI 285 platform leverages Cisco Networking with the Nexus 9364D-GX2A for the Converged and Compute Network and the Nexus 9300-FX3 for the Management Network.
Cisco Nexus 9300-GX2A Series Switches
The Cisco Nexus 9364D-GX2A is a 2-rack-unit (2RU) switch that supports 25.6 Tbps of bandwidth and 8.35 bpps across 64 fixed 400G QSFP-DD ports and 2 fixed 1/10G SFP+ ports. QSFP-DD ports also support native 200G (QSFP56), 100G (QSFP28), and 40G (QSFP+). Each port can also support 4 x 10G, 4 x 25G, 4 x 50G, 4 x 100G, and 2 x 200G breakouts.
It supports flexible configurations, including 128 ports of 200GbE or 256 ports of 100/50/25/10GE ports accommodating diverse AI/ML cluster requirements.

Figure 8. Nexus 9364D-GX2A
The Converged (North-South) Network handles storage and in-band management, linking the Enterprise IT environment to the Agentic AI platform. Built on Ethernet with RDMA over Converged Ethernet (RoCE), it supports current and new cloud and storage services as outlined in the AI Compute node configuration.
In addition to providing access to the AI agents and functions of the AI platform, this connection is utilized for all data ingestion from the Enterprise IT data during indexing and embedding into the Retrieval-Augmented Generation (RAG) process. It is also used for data retrieval during AI operations.
The Storage connectivity is exactly half that and described in the Storage Connectivity chapter.
The Compute (East-West) Network facilitates application communication between the GPUs across the Compute nodes of the AI platform. It is designed to achieve minimal latency and maximal performance using a rail-optimized, fully non-blocking fat tree topology with Cisco Nexus 9300 series switches.
Cisco Nexus 9000 series data Center switches deliver purpose-built networking solutions designed specifically to address these challenges, providing the foundation for scalable, high-performance AI infrastructures that accelerate time-to-value while maintaining operational efficiency and security. Built on Cisco’s custom Cloud Scale and Silicon One ASICs, these switches provide a comprehensive solution for AI-ready data centers.
Tip: In a pure Inference use case, the Compute Network is typically not necessary, but for training and fine-tuning operations it is a crucial component of the solution.
For configurations of up to five Scalable Units, the Compute and Converged Network are integrated utilizing the same switches. When deploying more than five units, it is necessary to separate the fabric.
The following table lists the configuration of the Cisco Nexus 9364D-GX2A.
Cisco Nexus 9300-FX3 Series Switch
The Cisco Nexus 93108TC-FX3P is a high-performance, fixed-port switch designed for modern data centers. It features 48 ports of 100M/1/2.5/5/10GBASE-T, providing flexible connectivity options for various network configurations. Additionally, it includes 6 uplink ports that support 40/100 Gigabit Ethernet QSFP28, ensuring high-speed data transfer and scalability.
Built on Cisco’s CloudScale technology, the 93108TC-FX3P delivers exceptional performance with a bandwidth capacity of 2.16 Tbps and the ability to handle up to 1.2 billion packets per second (Bpps).
This switch also supports advanced features such as comprehensive security, telemetry, and automation capabilities, which are essential for efficient network management and troubleshooting.

Figure 9. Cisco Nexus 93108TC-FX3P
The Out-of-Band (Management) Network encompasses all AI Compute node and BlueField-3 DPU base management controllers (BMC) as well as the network infrastructure management.
The following table lists the configuration of the Cisco Nexus 93108TC-FX3P.
Cisco Nexus Dashboard
Cisco Nexus Dashboard, included with every Cisco Nexus 9000 switch tiered licensing purchase, serves as a centralized hub that unifies disparate network configurations and views from multiple switches and data centers. For AI/ML fabric operations, it acts as the ultimate command center, from the initial setup of AI/ML fabric automation to continuous fabric analytics within few clicks.
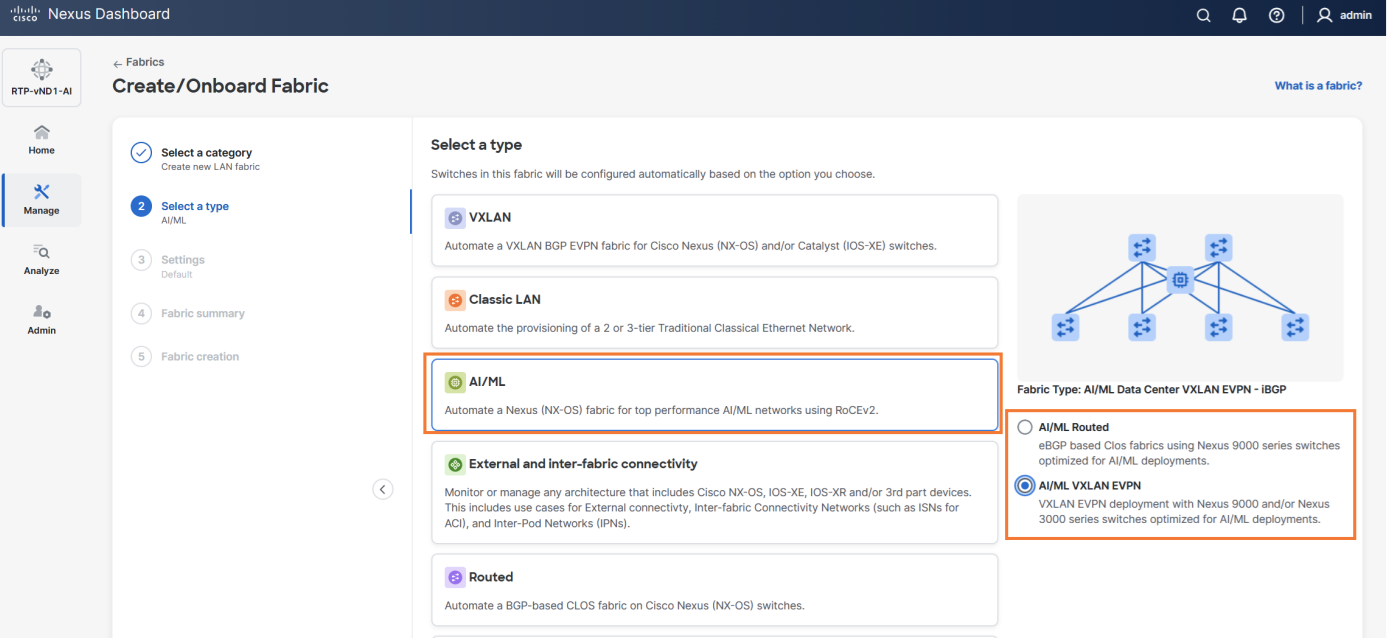
Figure 10. AI/ML Fabric Workflow on Nexus Dashboard
Key capabilities such as congestion scoring, PFC/ECN statistics, and microburst detection empower organizations to proactively identify and address performance bottlenecks for their AI/ML backend infrastructure.
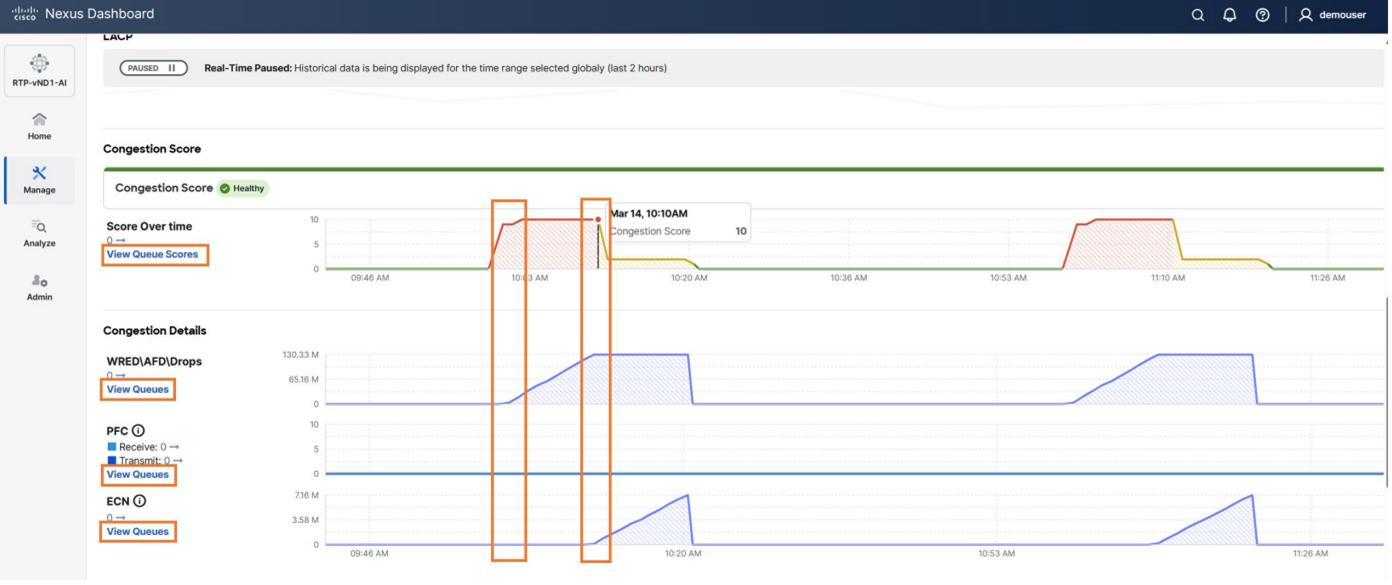
Figure 11. Congestion Score and Congestion Details on Nexus Dashboard
Advanced features like anomaly detection, event correlation, and suggested remediation ensure networks are not only resilient but also self-healing, minimizing downtime and accelerating issue resolution.
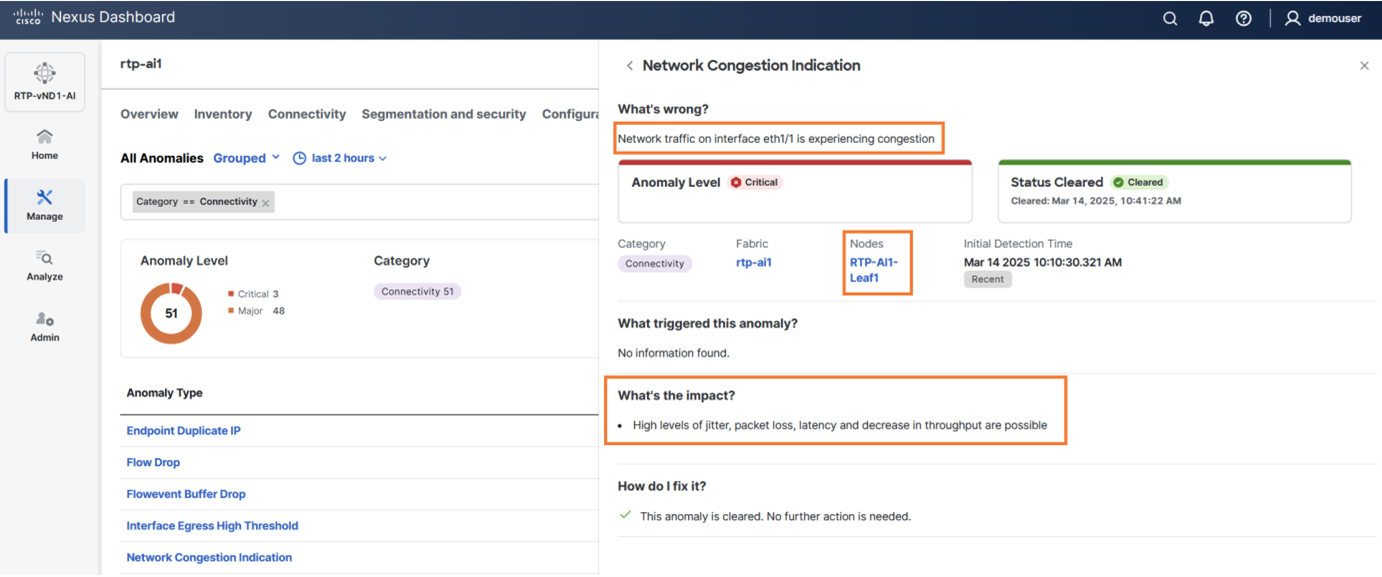
Figure 12. Anomaly Detection on Nexus Dashboard
Purpose-built to handle the high demands of AI workloads, the Cisco Nexus Dashboard transforms network management into a seamless, data-driven experience, unlocking the full potential of AI/ML fabrics.
Lenovo EveryScale Solution
The Server and Networking components and Operating System can come together as a Lenovo EveryScale Solution. It is a framework for designing, manufacturing, integrating and delivering data center solutions, with a focus on High Performance Computing (HPC), Technical Computing, and Artificial Intelligence (AI) environments.
Lenovo EveryScale provides Best Recipe guides to warrant interoperability of hardware, software and firmware among a variety of Lenovo and third-party components.
Addressing specific needs in the data center, while also optimizing the solution design for application performance, requires a significant level of effort and expertise. Customers need to choose the right hardware and software components, solve interoperability challenges across multiple vendors, and determine optimal firmware levels across the entire solution to ensure operational excellence, maximize performance, and drive best total cost of ownership.
Lenovo EveryScale reduces this burden on the customer by pre-testing and validating a large selection of Lenovo and third-party components, to create a “Best Recipe” of components and firmware levels that work seamlessly together as a solution. From this testing, customers can be confident that such a best practice solution will run optimally for their workloads, tailored to the client’s needs.
In addition to interoperability testing, Lenovo EveryScale hardware is pre-integrated, pre-cabled, pre-loaded with the best recipe and optionally an OS-image and tested at the rack level in manufacturing, to ensure a reliable delivery and minimize installation time in the customer data center.
Scalability
A fundamental principle of the solution design philosophy is its ability to support any scale necessary to achieve a particular objective.
In a typical Enterprise AI deployment initially the AI environment is being used with a single use case, like for example an Enterprise RAG pipeline which can connect a Large Language Model (LLM) to Enterprise data for actionable insights grounded in relevant data.
In its simplest form, leveraging the NVIDIA Blueprint for Enterprise RAG pipeline involves three NVIDIA Inference Microservices: a Retriever, a Reranker, and the actual LLM. This setup requires a minimum of three GPUs.
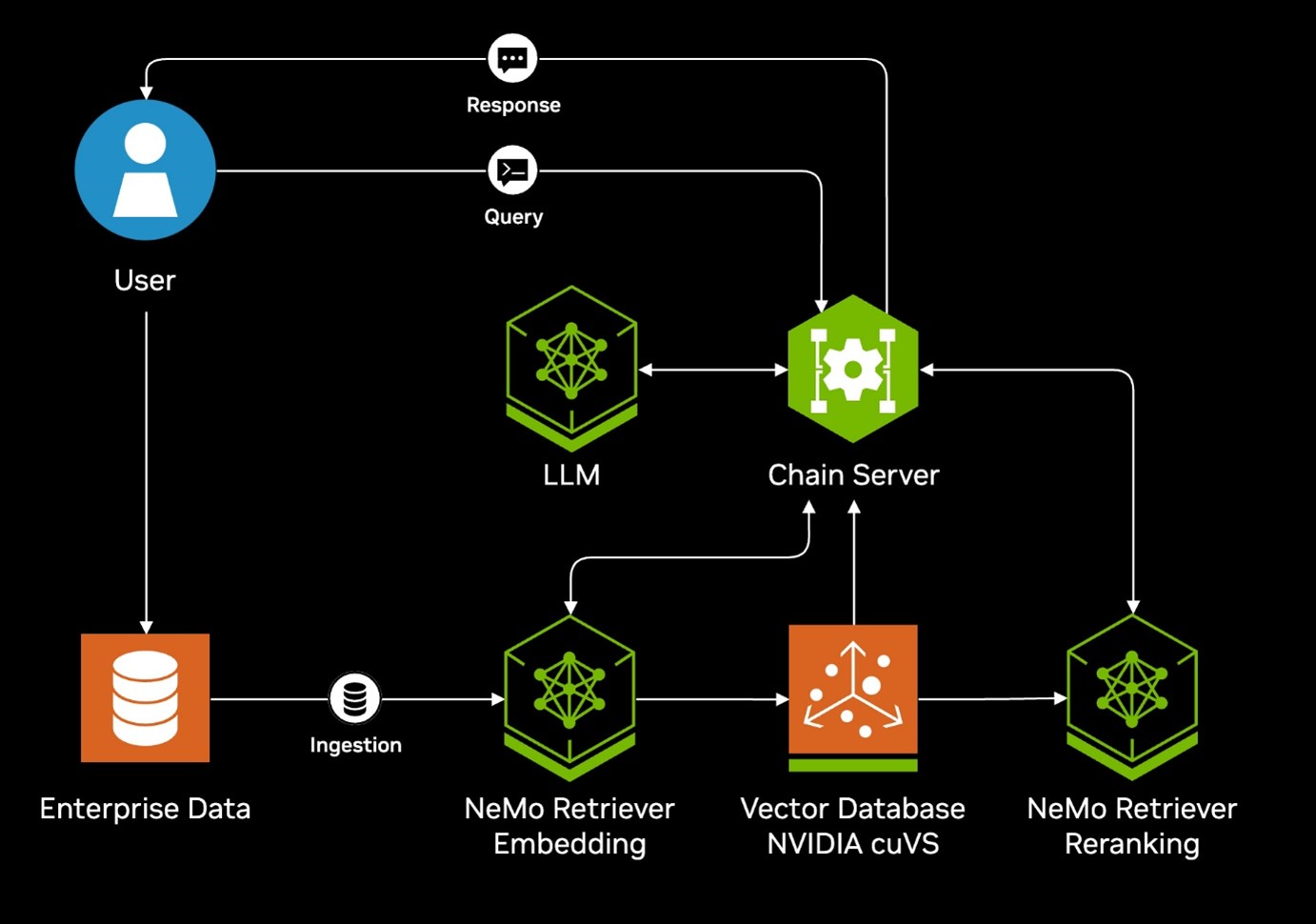
Figure 13. NVIDIA Blueprint Architecture Diagram
As the deployment of AI within the company continues to grow, the AI environment will be adapted to incorporate additional use cases, including Assistants or AI Agents. Additionally, it has the capacity to scale to support an increasing number of Microservices. Ultimately, most companies will maintain multiple AI environments operating simultaneously with their AI Agents working in unison.
The Lenovo Hybrid AI 285 with Cisco Networking platform has been designed to meet the customer where they are at with their AI application and then seamlessly scale with them through their AI integration. This is achieved through the introduction of the following:
A visual representation of the sizing and scaling of the platform is shown in the figure below.
Figure 14. Lenovo Hybrid AI 285 with Cisco Networking Scaling
Entry and AI Starter Kit Deployments
Entry deployment sizings are for customers that want to deploy their initial AI factory with 4-16x GPUs. Entry deployments have one or two SR675 V3 servers, with 8x GPUs per server (AI Compute Nodes). With two servers configured, the two servers are connected directly via the installed NVIDIA ConnectX-7 or NVIDIA BlueField adapters.
If additional networking is required or additional storage is required, then use the AI Starter Kit deployment, which supports up to 4x servers and up to 32x GPUs. The AI Starter Kit uses NVIDIA networking switches and ThinkSystem DM or DG external storage.
The following sections describe these deployments:
Entry sizing
Entry sizing starts with a single AI Compute node, equipped with four GPUs. Such entry deployments are ideal for development, application trials, or small-scale use, reducing hardware costs, control plane overhead, and networking complexity. With all components on one node, management and maintenance are simplified.
Entry sizing can also support two AI Compute nodes, directly connected together and without the need for external networking switches, to scale up to 16 GPUs if fully populated (2 nodes, 8x GPUs per node). The two nodes connect to the rest of your data center using existing networking in your data center.

Figure 15. Entry Deployment Rack View
| 4-8x GPUs | 8-16x GPUs | |
|---|---|---|
| Compute | 1x SR675 V3 | 2x SR675 V3 |
| Network adapters per server | Minimum ratio of 1 CX7 per 2 GPUs | Minimum ratio of 1 CX7 per 2 GPUs |
AI Starter Kits
For customers who want storage and/or networking in the Entry sizing, Lenovo and Cisco worked to develop AI Starter Kits with Cisco networking which allows up to 32 GPUs across 4 nodes, slightly more than the base 285 starter kit sizing which allows for up to only 24 GPUs. This sizing is for customers who do not plan to scale above 32 GPUs in the near future but still need an end-to-end solution for compute and storage.
Networking between the nodes is implemented using the Cisco 9332D-GX2B 200GbE switches and NVIDIA ConnectX-7 dual-port 200Gb adapters in each server.
Storage is implemented using either ThinkSystem DM or ThinkSystem DG Storage Arrays. Features include:
- Easy to deploy and scale for performance or capacity
- Unified file, object, and block eliminates AI data silos
- High performance NVMe flash and GPUdirect enable faster time to insights
- Confidently use production data to fine tune models with advanced data management features
The table and figure below show the hardware involved in various sizes of AI Starter Kit deployments.

Scalable Unit Deployment
For configurations beyond two nodes, it is advisable to deploy a full Scalable Unit along with the necessary network and service infrastructure, providing a foundation for further growth in enterprise use cases.
The fist SU consists of up to four AI Compute nodes, minimum five service nodes, and networking switches. When additional AI Compute Nodes are required, additional SUs of four AI Compute Nodes can be added.
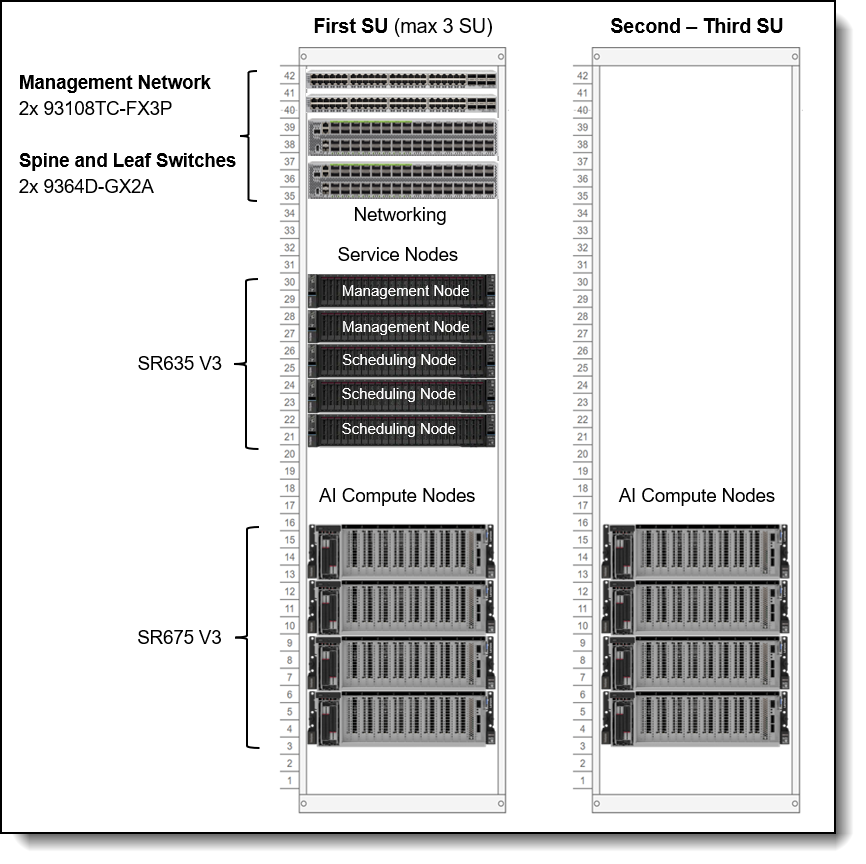
Figure 17. Scalable Unit Deployment
Networking is implemented using Cisco 93108TC-FX3P switches and CX-7 adapters in the AI Compute Nodes. The combination of these two pieces allows the user to take advantage of NVIDIA’s Spectrum-X networking, an Ethernet platform that delivers the highest performance for AI, machine learning, and natural language processing.
The networking decision depends on whether the platform is designed to support up to three Scalable Units in total, and whether it will handle exclusively inference workloads or also encompass future fine-tuning and re-training activities. Subsequently, the solution can be expanded seamlessly without downtime by incorporating additional Scalable Units, ultimately reaching a total of three as needed.
Performance
This document is meant to be used in tandem with the Hybrid AI 285 platform guide please see this section there.
AI Software Stack
This document is meant to be used in tandem with the Hybrid AI 285 platform guide please see this section there.
Storage Connectivity
This document is meant to be used in tandem with the Hybrid AI 285 platform guide please see this section there.
Lenovo AI Center of Excellence
This document is meant to be used in tandem with the Hybrid AI 285 platform guide please see this section there.
AI Services
This document is meant to be used in tandem with the Hybrid AI 285 platform guide please see this section there.
Lenovo TruScale
This document is meant to be used in tandem with the Hybrid AI 285 platform guide please see this section there.
Lenovo Financial Services
This document is meant to be used in tandem with the Hybrid AI 285 platform guide please see this section there.
Bill of Materials - 3 Scalable Unit (3 SU)
This section provides an example Bill of Materials (BoM) of one Scaleable Unit (SU) deployment with NVIDIA Spectrum-X.
This example BoM includes:
- 12x Lenovo ThinkSystem SR675 V3 with 8x NVIDIA H200 NVL GPUs per server (4 Servers/Scalable Unit)
- 5x Lenovo ThinkSystem SR635 V3
- 2x Cisco 9364D-GX2A Switches
- 2x Cisco 93108TC-FX3P Switches
Storage is optional and not included in this 3 SU BoM.
In this section:
3SU: ThinkSystem SR675 V3 BoM
3SU: ThinkSystem SR635 V3 BoM
3SU: Cisco 9364D-GX2A Switch BoM
3SU: Cisco 93108TC-FX3P Switch BoM
3SU: Rack Cabinet BoM
3SU: Cables and Transceivers BoM
Bill of Materials – Starter Kit
This section provides an example Bill of Materials (BoM) of Starter Kit deployment with Cisco switches.
This example BoM includes:
- 4x Lenovo ThinkSystem SR675 V3 with 8 × NVIDIA H200 NVL GPUs per server (The servers can be configured with less GPUs for an underpopulated configuration)
- 2x Cisco 9364D-GX2A Switches
- 2x Cisco 93108TC-FX3P Switches
- 1x Lenovo ThinkSystem DM7200 Storage
In this section:
Starter: ThinkSystem SR675 V3 BoM
Starter: ThinkSystem DM7200F Storage BoM
Starter: Cisco 9364D-GX2A Switch BoM
Starter: Cisco 93108TC-FX3P Switch BoM
Seller training courses
The following sales training courses are offered for employees and partners (login required). Courses are listed in date order.
-
VTT AI: Introducing the Lenovo Hybrid AI 285 Platform with Cisco Networking
2025-11-04 | 36 minutes | Partners Only
DetailsVTT AI: Introducing the Lenovo Hybrid AI 285 Platform with Cisco Networking
The Lenovo Hybrid AI 285 Platform enables enterprises of all sizes to quickly deploy AI infrastructures supporting use cases as either new greenfield environments or as an extension to current infrastructures.
Published: 2025-11-04
This session will describe the hardware architecture changes required to leverage Cisco networking hardware and the Cisco Nexus Dashboard within the Hybrid AI 285 Platform.
Topics include:
- Value propositions for the Hybrid AI 285 platform
- Updates for the Hybrid AI 285 platform
- Leveraging Cisco networking with the 285 platform
- Future plans for the 285 platform
Length: 36 minutes
Course code: DVAI220_PStart the training:
Partner link: Lenovo 360 Learning Center
-
Partner Technical Webinar - Lenovo AI Hybrid Factory offerings
2025-10-13 | 50 minutes | Employees and Partners
DetailsPartner Technical Webinar - Lenovo AI Hybrid Factory offerings
In this 50-minute replay, Pierce Beary, Lenovo Senior AI Solution Manager, review the Lenovo AI Factory offerings for the data center. Pierce showed how Lenovo is simplifying the AI compute needs for the data center with the AI 281, AI 285 and AI 289 platforms based on the NVIDIA AI Enterprise Reference Architecture.
Published: 2025-10-13
Tags: Artificial Intelligence (AI)
Length: 50 minutes
Course code: OCT1025Start the training:
Employee link: Grow@Lenovo
Partner link: Lenovo 360 Learning Center
-
Lenovo VTT Cloud Architecture: Empowering AI Innovation with NVIDIA RTX Pro 6000 and Lenovo Hybrid AI Services
2025-09-18 | 68 minutes | Employees Only
DetailsLenovo VTT Cloud Architecture: Empowering AI Innovation with NVIDIA RTX Pro 6000 and Lenovo Hybrid AI Services
Join Dinesh Tripathi, Lenovo Technical Team Lead for GenAI and Jose Carlos Huescas, Lenovo HPC & AI Product Manager for an in-depth, interactive technical webinar. This session will explore how to effectively position the NVIDIA RTX PRO 6000 Blackwell Server Edition in AI and visualization workflows, with a focus on real-world applications and customer value.
Published: 2025-09-18
We’ll cover:
- NVIDIA RTX PRO 6000 Blackwell Overview: Key specs, performance benchmarks, and use cases in AI, rendering, and simulation.
- Positioning Strategy: How to align NVIDIA RTX PRO 6000 with customer needs across industries like healthcare, manufacturing, and media.
- Lenovo Hybrid AI 285 Services: Dive into Lenovo’s Hybrid AI 285 architecture and learn how it supports scalable AI deployments from edge to cloud.
Whether you're enabling AI solutions or guiding customers through infrastructure decisions, this session will equip you with the insights and tools to drive impactful conversations.
Tags: Industry solutions, SMB, Services, Technical Sales, Technology solutions
Length: 68 minutes
Course code: DVCLD227Start the training:
Employee link: Grow@Lenovo
-
VTT AI: Introducing The Lenovo Hybrid AI 285 Platform with Cisco Networking
2025-08-26 | 54 minutes | Employees Only
DetailsVTT AI: Introducing The Lenovo Hybrid AI 285 Platform with Cisco Networking
Please view this session as Pierce Beary, Sr. AI Solution Manager, ISG ESMB Segment and AI explains:
Published: 2025-08-26
- Value propositions for the Hybrid AI 285 platform
- Updates for the Hybrid AI 285 platform
- Leveraging Cisco networking with the 285 platform
- Future plans for the 285 platform
Tags: Artificial Intelligence (AI), Technical Sales, ThinkSystem
Length: 54 minutes
Course code: DVAI220Start the training:
Employee link: Grow@Lenovo
-
VTT AI: Introducing the Lenovo Hybrid AI 285 Platform April 2025
2025-04-30 | 60 minutes | Employees Only
DetailsVTT AI: Introducing the Lenovo Hybrid AI 285 Platform April 2025
The Lenovo Hybrid AI 285 Platform enables enterprises of all sizes to quickly deploy AI infrastructures supporting use cases as either new greenfield environments or as an extension to current infrastructures. The 285 Platform enables the use of the NVIDIA AI Enterprise software stack. The AI Hybrid 285 platform is the perfect foundation supporting Lenovo Validated Designs.
Published: 2025-04-30
• Technical overview of the Hybrid AI 285 platform
• AI Hybrid platforms as infrastructure frameworks for LVDs addressing data center-based AI solutions.
• Accelerate AI adoption and reduce deployment risks
Tags: Artificial Intelligence (AI), Nvidia, Technical Sales, Lenovo Hybrid AI 285
Length: 60 minutes
Course code: DVAI215Start the training:
Employee link: Grow@Lenovo
Related publications and links
For more information, see these resources:
- Lenovo EveryScale support page:
https://datacentersupport.lenovo.com/us/en/solutions/ht505184 - x-config configurator:
https://lesc.lenovo.com/products/hardware/configurator/worldwide/bhui/asit/x-config.jnlp - Implementing AI Workloads using NVIDIA GPUs on ThinkSystem Servers:
https://lenovopress.lenovo.com/lp1928-implementing-ai-workloads-using-nvidia-gpus-on-thinksystem-servers - Making LLMs Work for Enterprise Part 3: GPT Fine-Tuning for RAG:
https://lenovopress.lenovo.com/lp1955-making-llms-work-for-enterprise-part-3-gpt-fine-tuning-for-rag - Lenovo to Deliver Enterprise AI Compute for NetApp AIPod Through Collaboration with NetApp and NVIDIA
https://lenovopress.lenovo.com/lp1962-lenovo-to-deliver-enterprise-ai-compute-for-netapp-aipod-nvidia
Trademarks
Lenovo and the Lenovo logo are trademarks or registered trademarks of Lenovo in the United States, other countries, or both. A current list of Lenovo trademarks is available on the Web at https://www.lenovo.com/us/en/legal/copytrade/.
The following terms are trademarks of Lenovo in the United States, other countries, or both:
Lenovo®
Lenovo Hybrid AI Advantage
ThinkAgile®
ThinkSystem®
XClarity®
The following terms are trademarks of other companies:
AMD and AMD EPYC™ are trademarks of Advanced Micro Devices, Inc.
Intel® is a trademark of Intel Corporation or its subsidiaries.
Linux® is the trademark of Linus Torvalds in the U.S. and other countries.
IBM® is a trademark of IBM in the United States, other countries, or both.
Other company, product, or service names may be trademarks or service marks of others.
Configure and Buy
Please select a locale
Full Change History
Course Detail
Employees Only Content
The content in this document with a is only visible to employees who are logged in. Logon using your Lenovo ITcode and password via Lenovo single-signon (SSO).
The author of the document has determined that this content is classified as Lenovo Internal and should not be normally be made available to people who are not employees or contractors. This includes partners, customers, and competitors. The reasons may vary and you should reach out to the authors of the document for clarification, if needed. Be cautious about sharing this content with others as it may contain sensitive information.
Any visitor to the Lenovo Press web site who is not logged on will not be able to see this employee-only content. This content is excluded from search engine indexes and will not appear in any search results.
For all users, including logged-in employees, this employee-only content does not appear in the PDF version of this document.
This functionality is cookie based. The web site will normally remember your login state between browser sessions, however, if you clear cookies at the end of a session or work in an Incognito/Private browser window, then you will need to log in each time.
If you have any questions about this feature of the Lenovo Press web, please email David Watts at dwatts@lenovo.com.





