

Top
Author
Published
28 Sep 2025Form Number
LP2304PDF size
12 pages, 340 KBSubscribed to LP2304.
Thank you for your feedback.
Abstract
This paper presents an interpretation of the MLPerf 5.1 benchmark results for the Lenovo ThinkSystem SR650 V4, a data center-grade server powered by Intel Xeon 6 processors. The focus is on CPU-only inferencing for modern AI workloads—covering Llama-3.1-8B, Whisper, DLRM v2, RetinaNet, and rGAT—and demonstrates how a well-tuned Xeon platform can deliver competitive latency, throughput, and cost-efficiency without discrete GPUs.
Results include per-model SLA-relevant latency metrics (TTFT, p99.9 e2e), throughput-to-concurrency sizing tables, and server vs offline scenario guidance that help IT teams right-size deployments for chatbots, speech-to-text, recommender systems, vision inference, and graph analytics.
This paper is aimed at enterprise infrastructure decision-makers, AI/ML platform architects, data-center operations leads, and performance-engineering specialists who evaluate CPU-based inference solutions for production AI workloads. By consolidating verified benchmark data, system configuration highlights, and practical sizing guidance, the paper enables readers to make evidence-based hardware selection and capacity-planning decisions for AI inferencing on Lenovo SR650 V4 servers。
Introduction
MLPerf is the industry-standard benchmark suite from MLCommons that provides objective and comparable performance metrics that allow organizations to assess hardware capabilities under standardized conditions. This paper presents an interpretation of the MLPerf 5.1 benchmark results for the Lenovo ThinkSystem SR650 V4, a data center-grade server powered by Intel Xeon 6 processors.

Figure 1. Lenovo ThinkSystem SR650 V4
The Lenovo results demonstrate the balanced performance of the ThinkSystem SR650 V4 across multiple domains: generative AI (Llama-3.1 8B), speech-to-text (Whisper), recommendation engines (DLRMv2), computer vision (RetinaNet), and graph analytics (rGAT). Each model’s results are analyzed in terms of throughput, latency, and practical fit for real-world use cases.
The SR650 V4 not only proves versatile across multimodal AI workloads but also delivers competitive global standings in MLPerf 5.1:
- 1st place on DLRMv2-99.9 Server
- 2nd place on Llama-3.1 8B Server
- 3rd place on Llama-3.1 8B Offline
- 3rd place on RetinaNet Server
- 3rd place on rGAT Offline
These achievements highlight Lenovo’s ability to provide data center solutions that combine high throughput, predictable latency, and enterprise-ready scalability, reinforcing the ThinkSystem SR650 V4 as a competitive choice for AI deployments at scale.
Cross-Model Summary & Comparison
This section provides a side-by-side comparison of the different models benchmarked on Lenovo ThinkSystem platforms. It highlights throughput, latency, and fit for use cases to provide a holistic view of model suitability.
Overall, the ThinkSystem platforms deliver balanced performance across diverse AI workloads. Llama-3.1 excels in language generation, Whisper in transcription, DLRMv2 in recommendation, RetinaNet in vision, and RGAT in graph workloads—demonstrating versatility of the system.
Verified MLPerf score of v5.1 Inference closed Llama3.1-8B, RetinaNet, DLRMV2 Server and Offline, rGAT and Whisper Offline. Retrieved from https://mlcommons.org/benchmarks/inference-datacenter/, Sep 2nd, 2025, entry 5.1-0063. The MLPerf name and logo are registered and unregistered trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See mlcommons.org for more information.
Llama-3.1 8B
This section summarizes MLPerf 5.1 benchmark results for Llama-3.1 8B. Results reflect both server (real-time) and offline (batch) performance.
- ThinkSystem SR650 V4 – 2nd place on Llama3.1-8b Server
- ThinkSystem SR650 V4 – 3rd place on Llama3.1-8b Offline
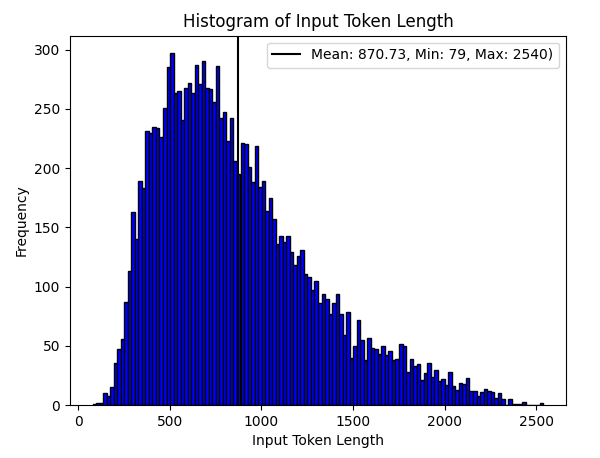
Since MLPerf uses the CNN/DailyMail dataset, the input and output length assumptions are critical for interpreting throughput and latency results.
Benchmark I/O configuration:
- Average input length: ~870 tokens (CNN/DailyMail article text)
- Maximum output length: 128 tokens (fixed by MLPerf harness)
The figure below shows the input length distribution.
Server Use Case Sizing
The following table summarizes the various use cases with expected performance associated with them.
The formulas to generate the above table are as follows:
- P99.9 latency = TTFT + (Output tokens L -1 ) * TPOT, where TTFT = 2.37s, TPOT = 113ms
- Sustained RPS = Sustained Token/s / Output Tokens(L), Where Sustained Tokens/s = 275.78 tokens/s
- Concurrent Sessions = P99.9 latency * Sustained RPS
Offline Use Case Sizing
The following table demonstrates the model capacity for each use cases of batch processing.
Key Takeaways – Llama3.1 8B
The key takeaways from these results are as follows:
- Consistent SLA – Predictable p99.9 latency, suitable for mission-critical apps.
- Balanced Performance – ~275 tok/s, TPOT = 113 ms, 33–43 concurrent users.
- Scalable Use Cases – Fast for short chats (~8s), practical for longer tasks (~36s).
- Enterprise Efficiency – Strong price-performance on Intel Xeon 6 ThinkSystem SR650 V4
Whisper
This section contains use-case tables and highlights for Whisper benchmark. Whisper is an advanced speech-to-text tool from OpenAI that can quickly turn spoken words into accurate written text. It works across many languages and is designed to handle real-world situations like different accents or background noise, making it a powerful solution for everyday transcription and translation needs.
Whisper Offline Use Case Sizing
The following table showcase the model performance under various use cases. We assume clips with an average length of 30-second.
The formula to generate the above table are as follows:
- Concurrent Streams = Sustained RPS * 30, where Sustained RPS = 18.57 sample/s
DLRMv2
This section contains use case tables, and highlights for DLRMv2. DLRMv2 (Deep Learning Recommendation Model v2) is a state-of-the-art model developed for powering recommendation systems, such as those used in e-commerce, ads, and content platforms. It efficiently processes both numerical and categorical data to deliver highly accurate, real-time personalized recommendations at scale.
- ThinkSystem SR650 V4 – 1st place on dlrm-v2-99.9 Server
DLRMv2 Use Case Sizing
The following table demonstrates the model capacity for each use cases of batch processing.
The ThinkSystem V4 platform shows strong suitability for personalization workloads, covering both real-time (ads, e-commerce) and high-volume offline (catalog re-ranking) scenarios.
RetinaNet
This section contains use case tables and highlights for RetinaNet. RetinaNet is a deep learning model designed for object detection, capable of identifying and locating multiple objects within an image. Known for balancing speed and accuracy, it introduced the innovative “focal loss” technique, which makes it especially effective at detecting smaller or less frequent objects in real-world scenarios. It has been widely adopted in industries such as security, retail, healthcare, and autonomous driving, where reliable object detection is essential for video surveillance, inventory monitoring, medical imaging, and self-driving perception systems.
- ThinkSystem SR650 V4 – 3rd place on RetinaNet Server
RetinaNet Server Use Case Sizing
The following table show case the model fitness of live streaming use cases.
RetinaNet Offline Use Case Sizing
The following table show case the model fitness of batch processing use cases.
The offline throughput shows that the ThinkSystem server can process over 40.5m images per day per server, enabling massive-scale video backlog analysis, incident detection, and compliance audit workloads.
RGAT
This section contains use case tables and highlights for RGAT. rGAT (relational Graph Attention Network) is a graph neural network model designed to capture relationships in complex, structured data by applying attention mechanisms across nodes and edges. This makes it especially powerful for tasks that require understanding connections, such as fraud detection, recommendation systems, and knowledge graph reasoning. It has been widely used in industries like finance, e-commerce, and social media, where uncovering hidden patterns and relationships is critical for decision-making and risk management.
- ThinkSystem SR650 V4 – 3rd place on rGAT Offline
RGAT Use Case Sizing (Offline)
The Lenovo system achieved 13.6k samples/sec offline throughput on the rGAT benchmark in MLPerf 5.1. This performance comfortably exceeds the throughput requirements across diverse real-world graph AI use cases such as fraud detection, recommendation systems, drug discovery, and knowledge graph completion.
Note: In MLPerf 5.1, Lenovo’s system achieved 13.6k samples/sec on rGAT in the offline benchmark. This demonstrates strong throughput capacity, comfortably above the requirements of common industry workloads like fraud detection (≥5k txn/sec) and recommendation graphs (≥10k items/sec). However, since MLPerf offline mode does not evaluate end-to-end latency, these results should be viewed as throughput potential under batch processing conditions. Real-time latency compliance requires additional validation.
Summary
The MLPerf 5.1 results for Lenovo ThinkSystem SR650 V4 with Intel Xeon 6 CPUs demonstrate a strong balance of throughput, latency, and efficiency across a wide range of AI models:
- Llama-3.1 8B provides consistent performance for generative tasks with predictable latencies
- Whisper delivers real-time transcription readiness at scale
- DLRMv2 achieves extremely low-latency, high-throughput personalized recommendations
- RetinaNet supports both live object detection and massive offline video analysis
- rGAT comfortably exceeds throughput requirements for graph-based workloads such as fraud detection and knowledge graph completion.
These outcomes reinforce that Lenovo’s ThinkSystem platforms are not optimized for just one workload but can meet the demands of multimodal AI use cases. Importantly, while offline throughput results demonstrate impressive processing capacity, latency-sensitive scenarios require careful interpretation and, in some cases, additional validation in production environments.
Overall, the findings establish Lenovo ThinkSystem SR650 V4 as a versatile, enterprise-ready platform that can scale AI workloads efficiently while maintaining competitive price-performance ratios.
System Configuration and Software Environment
The following table lists the server configuration.
Author
Kelvin He is an AI Data Scientist at Lenovo. He is a seasoned AI and data science professional specializing in building machine learning frameworks and AI-driven solutions. Kelvin is experienced in leading end-to-end model development, with a focus on turning business challenges into data-driven strategies. He is passionate about AI benchmarks, optimization techniques, and LLM applications, enabling businesses to make informed technology decisions.
Trademarks
Lenovo and the Lenovo logo are trademarks or registered trademarks of Lenovo in the United States, other countries, or both. A current list of Lenovo trademarks is available on the Web at https://www.lenovo.com/us/en/legal/copytrade/.
The following terms are trademarks of Lenovo in the United States, other countries, or both:
Lenovo®
ThinkSystem®
The following terms are trademarks of other companies:
Intel, the Intel logo and Xeon are trademarks of Intel Corporation or its subsidiaries.
Other company, product, or service names may be trademarks or service marks of others.
Configure and Buy
Please select a locale
Full Change History
Course Detail
Employees Only Content
The content in this document with a is only visible to employees who are logged in. Logon using your Lenovo ITcode and password via Lenovo single-signon (SSO).
The author of the document has determined that this content is classified as Lenovo Internal and should not be normally be made available to people who are not employees or contractors. This includes partners, customers, and competitors. The reasons may vary and you should reach out to the authors of the document for clarification, if needed. Be cautious about sharing this content with others as it may contain sensitive information.
Any visitor to the Lenovo Press web site who is not logged on will not be able to see this employee-only content. This content is excluded from search engine indexes and will not appear in any search results.
For all users, including logged-in employees, this employee-only content does not appear in the PDF version of this document.
This functionality is cookie based. The web site will normally remember your login state between browser sessions, however, if you clear cookies at the end of a session or work in an Incognito/Private browser window, then you will need to log in each time.
If you have any questions about this feature of the Lenovo Press web, please email David Watts at dwatts@lenovo.com.





