

Top
Author
Published
30 Jul 2025Form Number
LP2261PDF size
8 pages, 2.7 MBSubscribed to LP2261.
Thank you for your feedback.
Abstract
Generative AI is reshaping visual content creation by enabling text-to-image diffusion models that transform natural language inputs into high-quality, photorealistic images. While these models are traditionally deployed on GPU-based infrastructure due to their high compute demands, the associated costs and resource constraints can hinder broad adoption and scalability.
This paper explores a CPU-optimized approach using OpenVINO to accelerate inference for text-to-image diffusion models on Lenovo ThinkSystem servers equipped with the latest Intel Xeon Scalable processors (including Intel Xeon 6). By utilizing advanced CPU features such as Intel Advanced Matrix Extensions (Intel AMX) and OpenVINO’s optimized execution runtime, organizations can achieve low-latency, high-throughput performance at a significantly reduced total cost of ownership. This solution enables broader accessibility, operational flexibility, and efficient scaling of generative AI workloads without relying exclusively on GPUs.
It is expected that the reader will have a general familiarity with Python, Linux-based terminal environments, and the Hugging Face Transformers library. Readers should also understand concepts like virtual environments and basic deep learning workflows. Prior experience with model inference or hardware acceleration frameworks (e.g., OpenVINO, ONNX Runtime, TensorRT) will be helpful but is not required.
Introduction
Text-to-image diffusion models, such as Stable Diffusion XL, represent the frontier of generative AI, offering the ability to create realistic images directly from textual descriptions. These models, however, are computationally intensive and often require high-performance hardware typically found in GPU-based systems. This dependency on GPUs can present cost, availability, and power efficiency challenges—particularly at scale.
To address these limitations, this paper explores an alternative approach: accelerating text-to-image model inference on CPU-based infrastructure using Intel’s OpenVINO toolkit and the AI acceleration capabilities of Intel Advanced Matrix Extensions (AMX), available in 5th and 6th Gen Intel Xeon Scalable processors.
Figure 1 illustrates sample images generated using OpenVINO with Stable Diffusion XL.

Figure 1: Example images generated using stabilityai’s stable-diffusion-xl model with OpenVINO
This paper describes the following:
- Introduction to the Intel Xeon platform, explaining how AMX enhances deep learning performance
- A step-by-step walk-through of the implementation of Stable Diffusion XL using OpenVINO
- Performance benchmarking data comparing native Hugging Face inference with OpenVINO-accelerated pipelines
Intel Xeon processors and Intel AMX
At the heart of this solution are Lenovo ThinkSystem servers with Intel Xeon processors. These processors include Intel Advanced Matrix Extensions (Intel AMX), which enable direct acceleration of deep learning inference and training workloads on the CPU.
By eliminating the dependency on discrete accelerators for many AI tasks, organizations benefit from simplified infrastructure, streamlined deployment, and a reduced total cost of ownership. With backward compatibility to prior generation Intel Xeon platforms, businesses can also preserve existing investments and accelerate time to value through seamless system upgrades.
In this paper we are using the ThinkSystem SR650 V3 as the basis for our testing. The SR650 V3 is based on 5th Gen Intel Xeon processors. These processors deliver up to:
- 14× PyTorch inference performance improvement over 3rd Gen Intel Xeon
- 5× better performance per watt compared to 4th Gen AMD EPYC
- Sub-100ms latency on large language models with up to 20B parameters
It is expected that you would get even greater results using the ThinkSystem SR650 V4 with the latest Intel Xeon 6700P processors.
Diffusion workflow
This section outlines how to run an accelerated text-to-image diffusion model using OpenVINO on Intel CPUs.
The steps are as follows:
- Create a virtual environment (Optional)
We recommend you install the uv package to create a virtual python environment to avoid dependency issues and quickly download needed python libraries. Otherwise, if you have a clean install or a containerized machine, you can install the needed libraries directly without a virtual environment.
Run the following in your Linux terminal:
curl -LsSf https://astral.sh/uv/install.sh | sh uv venv diffusion-env source diffusion-env/bin/activate - Download dependencies
Install the necessary OpenVINO python libraries as well as the optimum command line tool to easily obtain pre-trained models from huggingface.
uv install optimum[openvino] uv pip install -U --pre --extra-index-url https://storage.openvinotoolkit.org/simple/wheels/nightly openvino openvino-tokenizers openvino-genai - Download Models & Convert to OpenVINO-IR
Using the optimum command line interface download a huggingface model of your choosing and convert it to the OpenVINO Intermediate Representation.
Below is an example using the stable-diffusion-xl model due to its visually impressive results.
optimum-cli export openvino --model stabilityai/stable-diffusion-xl-base-1.0 /~ /.cache/huggingface/hub/stable-diffusion-xl-base-1.0-ov - Create Inference Pipeline and Generate Image
Begin using the model to generate a sample image using the following python script. The results should be a 1024x1024 image similar to Figure 2.
model_path = "/home/lenovoai/.cache/huggingface/hub/stable-diffusion-xl-base-1.0-ov/" prompt = "A fox wearing a detective trench coat solving a mystery" pipe = ov_genai.Text2ImagePipeline(model_path, "CPU") image_tensor = pipe.generate(prompt, num_inference_steps=40, rng_seed=42) # Post-Process and Save Image image = Image.fromarray(image_tensor.data[0]) image.save("output-img.png")
Figure 2: Example output from prompt: “A fox wearing a detective trench coat solving a mystery”
OpenVINO performance
To assess the performance benefits of OpenVision and Intel Xeon processor-optimized inference, a benchmark was conducted comparing Stable Diffusion XL-1.0 executed with native Hugging Face libraries with the OpenVINO toolkit on 5th Gen Intel Xeon processors. The results are shown in Figure 3.
Stable Diffusion XL-1.0 was selected due to its computational intensity and model complexity, representing a demanding use case for generative AI workloads. The test involved generating 30 images, each using 40 inference steps.
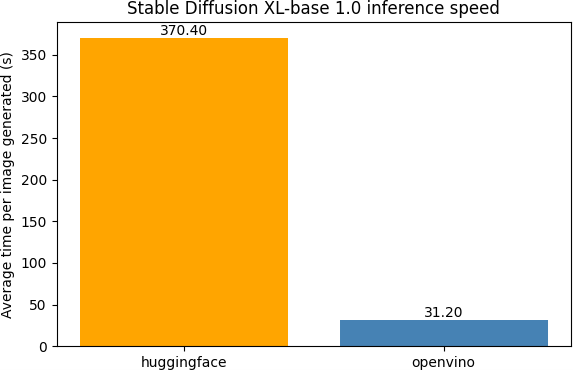
Figure 3. Inference speed comparison on Stable Diffusion XL-1.0 averaged over 30 images with 40 inference steps each; see Hardware Details for exact hardware specifications
Results demonstrate that native Hugging Face pipelines are not fully optimized to take advantage of the AI acceleration capabilities of Intel Advanced Matrix Extensions (Intel AMX) as implemented in 5th Gen Intel Xeon processors. Using the native implementation, the average time to generate a single image was approximately six minutes.
In contrast, OpenVINO significantly improves inference speed by applying graph-level optimizations and utilizing low-level hardware acceleration resulting in the average to perform the same task of thirty seconds, a 12x performance improvement. These enhancements enable more efficient execution of compute-intensive diffusion models on CPU-based infrastructure, delivering faster time-to-result and improving system throughput for AI-driven image generation workloads. This performance uplift makes CPU-based inference a viable, cost-effective alternative for organizations deploying large-scale generative AI applications.
Conclusion
This paper highlights a powerful, cost-effective solution for Generative AI: high-performance text-to-image inference on CPU-based infrastructure using Lenovo ThinkSystem servers with Intel Xeon Scalable processors and the OpenVINO toolkit. By harnessing Intel AMX acceleration in 5th Gen Intel Xeon Processors and OpenVINO’s optimized model execution, organizations can achieve up to 12× faster inference over native libraries—without relying on discrete GPUs.
The result is a highly scalable, energy-efficient solution that reduces total cost of ownership, simplifies deployment, and supports sustainable AI operations. For enterprises looking to scale generative AI across production environments, Lenovo and Intel deliver a robust, ready-to-deploy platform that meets today’s performance, efficiency, and operational demands.
The latest Intel Xeon 6 processors expand on the capabilities of their predecessors by offering broader support for Intel AMX, higher core counts, and improved power efficiency. Users can expect even faster inference times, greater throughput, and better energy-per-inference metrics. These enhancements further close the performance gap between CPU and GPU solutions while maintaining the flexibility and scalability of general-purpose server infrastructure. This makes Intel Xeon 6 an ideal foundation for next-generation generative AI deployments across enterprise, edge, and cloud environments.
Ready to accelerate your AI strategy? Explore how Lenovo and Intel can help your organization deploy high-performance, efficient, and reliable generative AI solutions at scale.
Hardware Details
The following table lists the key components of the server we used in our performance tests.
Author
Eric Page is an AI Engineer at Lenovo. He has 6 years of practical experience developing Machine Learning solutions for various applications ranging from weather-forecasting to pose-estimation. He enjoys solving practical problems using data and AI/ML.
Trademarks
Lenovo and the Lenovo logo are trademarks or registered trademarks of Lenovo in the United States, other countries, or both. A current list of Lenovo trademarks is available on the Web at https://www.lenovo.com/us/en/legal/copytrade/.
The following terms are trademarks of Lenovo in the United States, other countries, or both:
Lenovo®
ThinkSystem®
The following terms are trademarks of other companies:
AMD and AMD EPYC™ are trademarks of Advanced Micro Devices, Inc.
Intel®, the Intel logo, OpenVINO®, and Xeon® are trademarks of Intel Corporation or its subsidiaries.
Linux® is the trademark of Linus Torvalds in the U.S. and other countries.
Other company, product, or service names may be trademarks or service marks of others.
Configure and Buy
Please select a locale
Full Change History
Course Detail
Employees Only Content
The content in this document with a is only visible to employees who are logged in. Logon using your Lenovo ITcode and password via Lenovo single-signon (SSO).
The author of the document has determined that this content is classified as Lenovo Internal and should not be normally be made available to people who are not employees or contractors. This includes partners, customers, and competitors. The reasons may vary and you should reach out to the authors of the document for clarification, if needed. Be cautious about sharing this content with others as it may contain sensitive information.
Any visitor to the Lenovo Press web site who is not logged on will not be able to see this employee-only content. This content is excluded from search engine indexes and will not appear in any search results.
For all users, including logged-in employees, this employee-only content does not appear in the PDF version of this document.
This functionality is cookie based. The web site will normally remember your login state between browser sessions, however, if you clear cookies at the end of a session or work in an Incognito/Private browser window, then you will need to log in each time.
If you have any questions about this feature of the Lenovo Press web, please email David Watts at dwatts@lenovo.com.





