

Top
Authors
Published
31 Jul 2025Form Number
LP2268PDF size
11 pages, 378 KBSubscribed to LP2268.
Thank you for your feedback.
Table of Contents
Abstract
Scikit-learn is an open-source Python library that bundles a broad suite of supervised- and unsupervised-learning algorithms—along with preprocessing, model-selection, and evaluation utilities—so practitioners can build and validate machine-learning pipelines with just a few lines of code.
Standard scikit-learn executes many algorithms in a single thread, which leaves modern multi-core Intel Xeon processors under-utilized during model training. Intel Extension for Scikit-learn (sklearn-intelex) transparently patches scikit-learn to invoke highly-optimized oneAPI Data Analytics Library (oneDAL) primitives, delivering significant wall-clock speed-ups with near-identical model accuracy.
In this paper we benchmark common supervised and unsupervised learning tasks—classification, regression, clustering—comparing training and inference wall-clock time and predictive accuracy between vanilla scikit-learn and scikit-learn-intelex on a Lenovo ThinkSystem SR650 V4 server. Results show:
- Up to 15× faster training for ensemble methods (e.g., Random Forest, Gradient Boosting)
- Up to 87× faster K-Means clustering
- 10–35× faster linear/GLM models
While keeping accuracy within ±0.2 percentage points of the baseline. (Each factor is the ratio of vanilla scikit-learn training time to intel-patched training time on the same workload.)
This paper is for data scientists, ML engineers, and performance-minded architects who already understand core scikit-learn APIs (fit/predict, pipelines) and basic ML concepts (train-test split, common metrics). We assume readers are comfortable with Python and seek practical guidance on extracting more performance from Intel Xeon-based infrastructure without rewriting their code.
Introduction
The first paper of this series demonstrated how Modin alleviates Pandas I/O and transformation bottlenecks. Once data is prepared, model training becomes the next compute-intensive stage. The Intel extension for scikit-learn and boost trees offers a drop-in upgrade—one line of code—that unlocks multicore performance without rewriting pipelines.
Once data is cleansed, model training becomes the next computational hotspot. Rather than re-implementing algorithms, a single call to patch_sklearn() turns Intel Extension for Scikit-learn into a true drop-in accelerator, tapping every CPU core without touching the rest of your pipeline. Intel’s extension re-uses scikit-learn’s Python API yet dispatches heavy-lifting to vectorized C++ kernels. This paper quantifies those benefits.
These experiments were conducted on Lenovo ThinkSystem SR650 V4. The Lenovo ThinkSystem SR650 V4 is an ideal 2-socket 2U rack server for customers that need industry-leading reliability, management, and security, as well as maximizing performance and flexibility for future growth. The SR650 V4 is based on two Intel Xeon 6700-series or Xeon 6500-series processors, with Performance-cores (P-cores), formerly codenamed "Granite Rapids-SP".
The SR650 V4 is designed to handle a wide range of workloads, such as databases, virtualization and cloud computing, virtual desktop infrastructure (VDI), infrastructure security, systems management, enterprise applications, collaboration/email, streaming media, web, and HPC.

Benchmark methodology
To quantify the benefit of sklearn-intelex over vanilla scikit-learn we followed a controlled, repeatable workflow that isolates the effects of hardware, library implementation, and workload mix. The methodology is organized around three building blocks—metrics, algorithms & datasets, and procedure—described below.
Topics in this section:
Metrics
The list below defines the performance and quality signals we record for every experiment:
- Primary– Training wall-clock time (median of 5 cold-start runs).
- Guardrail– Predictive quality: accuracy (classification), Mean Square Error (regression), silhouette (clustering).
Algorithms and datasets
We chose widely used classical algorithms paired with publicly available datasets large enough to stress a multi core CPU yet still runable on a single server. The following table groups them by ML task and shows which metric serves as the speed target (primary) and which protects model fidelity (guardrail).
Procedure
The following run-loop is executed for each algorithm × dataset combination to generate the timing and accuracy numbers reported later. By repeating the exact workflow twice—once with stock scikit-learn (“vanilla”) and once with Intel’s patched version—we isolate the speed-up attributable solely to sklearn-intelex.
- Preprocess dataset and cache in memory.
Load the raw dataset, perform any required cleaning/encoding, and hold the resulting arrays in memory so file-I/O never contaminates timing results.
- Select one of the following implementations:
- Intel run: call from sklearnex import patch_sklearn; patch_sklearn() to monkey-patch scikit-learn estimators with oneDAL-backed, multi-threaded versions.
- Baseline (“vanilla”) run: skip the patch—i.e., import and use scikit-learn exactly as shipped on PyPI—so all algorithms execute on a single core.
- Measure training & inference.
Fit the model five cold-start times, wrapping both fit() and immediate predict() calls with timer(). Record the median wall-clock duration along with the selected guard-rail metric (accuracy, MSE, etc.)
- Evaluate on 20 % hold-out set.
Captures guard-rail quality metrics (accuracy, MSE, silhouette, etc.)
- Shut down the Python process between Intel and baseline runs.
Flushes OS caches and prevents warm-cache bias.
Results
This section presents the quantitative (Tables 2 & 3) and visual ( Figures 2 & 3) outcomes of our benchmarking campaign, detailing how sklearn-intelex affects training speed, inference speed, and predictive accuracy across every algorithm–dataset pair. We first summarize aggregate speed-ups and accuracy preservation, then highlight noteworthy patterns and edge cases observed during the experiments.
Training time speed-ups
To understand where Intel Extension for scikit-learn delivers the most value, we broke training latency down by task and algorithm.
The table below reports the median wall-clock training time (in ms) for each workload with sklearn-intelex activated (“Intel Accelerator”) versus unmodified scikit-learn (“Vanilla Algorithm”) and the resulting speed-up factor. Use these values in tandem with Figure 2 to see how acceleration varies across model families.
Figure 2 shows how much Intel’s patch slashes training compared to Vanilla Sklearn
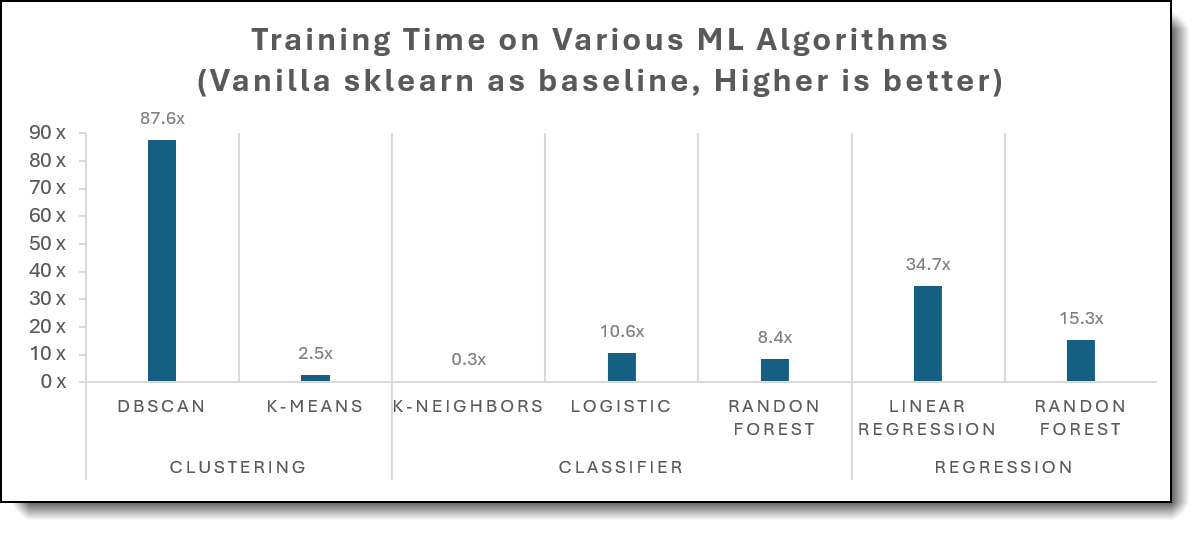
Figure 2. Training Times comparison
Inferencing time speed-ups
After training speed, the next question for production pipelines is how fast each model can deliver predictions. We therefore timed the predict() call for every algorithm–dataset pair under the same cold-start conditions used in the training benchmarks.
The table below summarizes the results. For each workload it lists the median wall-clock latency with Intel Extension for scikit-learn (“Intel Accelerator”) versus unmodified scikit-learn (“Vanilla Algorithm”) and the resulting speed-up factor.
The following figure shows how Intel’s extension cutting inference latencies.
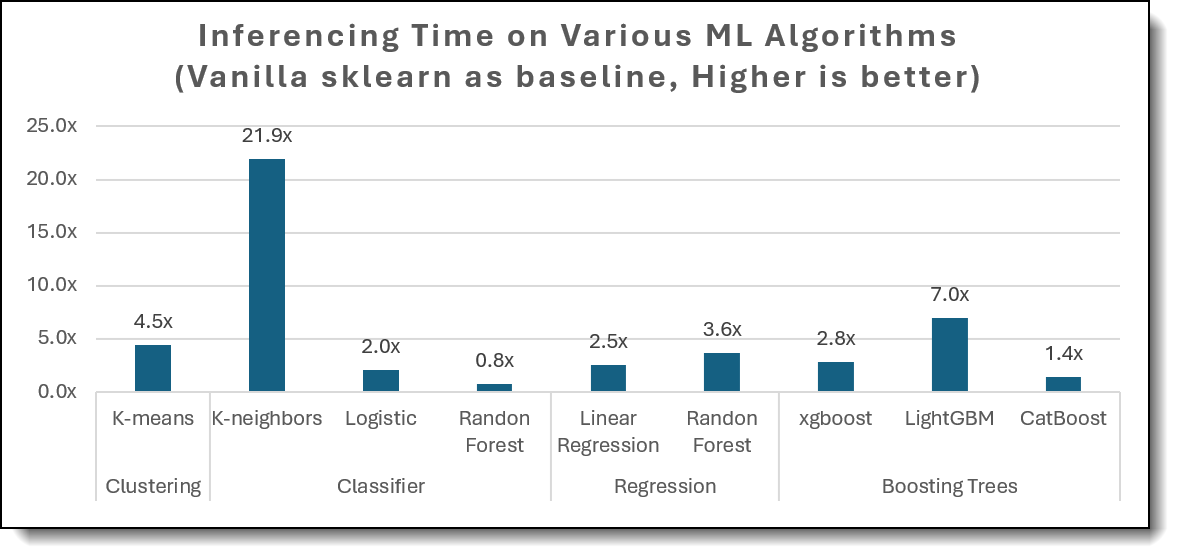
Figure 3. Inferencing Time comparison
Accuracy preservation
Across all tasks the accuracy/MSE deviation relative to vanilla scikit-learn remained within ±0.2%, validating the extension’s numerical equivalence.
The following table confirms that the Intel Extension preserves model quality. Across all workloads, the guard rail metrics (accuracy, log loss, MSE, inertia, etc.) differ from vanilla scikit-learn by ≤ 0.2 %.
Observations
Together, these results distill into three headline takeaways:
- Training efficiency soars (Table 1).
Intel Extension for Scikit-learn cuts fit-time by double- to triple-digit factors: 6× for DBSCAN, 34.7× for Linear Regression, 10.6× for Logistic Regression, and 8.4× for Random ForestClassifier—while K-NN lags (0.3×) because that routine is still un-optimized.
- Inference gets quicker too (Table 2).
Prediction latency shrinks 4-22× for most workloads (21.9× on K-NN, 4.5× on K-means, 3.6× on Random ForestRegressor, 2.5× on Linear Regression). The only regression is a mild 0.8× slow-down on Random Forest Classifier, where patch-overhead outweighs gains on the small test set.
- Model quality is preserved (Table 3).
Accuracy, MSE, inertia, and Davies-Bouldin all stay within ±0.2% of vanilla scikit-learn, confirming that the speed-ups come with virtually zero impact on predictive performance.
A single line call to Intel Extension for Scikit-learn instantly unleashes full multicore power without altering your existing pipeline. For organizations already using pandas DataFrames and scikit-learn, migrating preprocessing to Modin and model training to scikit-learn-intelex forms a cohesive optimization path entirely on CPU, mitigating GPU scarcity and cost.
Conclusion
The combined results in Tables 1 and 2 show that optimization gains vary by phase. Algorithms such as k-Nearest Neighbors train ∼0.3× slower with Intel Extension yet deliver ≈22× faster inference, making them attractive for prediction-heavy workloads. In contrast, Random Forest Classifier enjoys an ≈8× training boost but a slight 0.8× slowdown at inference on the small test set, favoring experimentation cycles over low-latency scoring unless additional tuning is applied. Most other methods (DBSCAN, Linear/Logistic Regression, K-means, Random Forest Regressor) accelerate both phases.
Choosing where to deploy the extension should therefore consider the complete fit to predict pipeline and the dominant cost in production.
Overall, on a dual-socket Intel Xeon platform, Intel Extension for Scikit-learn delivers 2-87× faster training times on mainstream ML algorithms while preserving baseline accuracy. These gains translate directly to higher experiment throughput, faster iteration cycles, and improved server utilization for production retraining workloads.
Test environment
Our test server had the hardware and software configuration listed in the following table.
References
See the following web pages for more information:
- Lenovo ThinkSystem SR650 V4 product guide
https://lenovopress.lenovo.com/lp2127-thinksystem-sr650-v4-server - Lenovo ThinkSystem SR650 V4 datasheet
https://lenovopress.lenovo.com/datasheet/ds0194-lenovo-thinksystem-sr650-v4 - Intel Extension for Scikit-learn – GitHub repository
https://github.com/uxlfoundation/scikit-learn-intelex/tree/main/examples/notebooks - Intel Extension for Scikit-learn documentation
https://www.intel.com/content/www/us/en/developer/tools/oneapi/scikit-learn.html - Intel oneAPI Data Analytics Library
https://www.intel.com/content/www/us/en/developer/tools/oneapi/onedal.html#gs.nmjeoe - scikit-learn User Guide
https://scikit-learn.org/stable/user_guide.html
Authors
Kelvin He is an AI Data Scientist at Lenovo. He is a seasoned AI and data science professional specializing in building machine learning frameworks and AI-driven solutions. Kelvin is experienced in leading end-to-end model development, with a focus on turning business challenges into data-driven strategies. He is passionate about AI benchmarks, optimization techniques, and LLM applications, enabling businesses to make informed technology decisions.
David Ellison is the Chief Data Scientist for Lenovo ISG. Through Lenovo’s US and European AI Discover Centers, he leads a team that uses cutting-edge AI techniques to deliver solutions for external customers while internally supporting the overall AI strategy for the Worldwide Infrastructure Solutions Group. Before joining Lenovo, he ran an international scientific analysis and equipment company and worked as a Data Scientist for the US Postal Service. Previous to that, he received a PhD in Biomedical Engineering from Johns Hopkins University. He has numerous publications in top tier journals including two in the Proceedings of the National Academy of the Sciences.
Trademarks
Lenovo and the Lenovo logo are trademarks or registered trademarks of Lenovo in the United States, other countries, or both. A current list of Lenovo trademarks is available on the Web at https://www.lenovo.com/us/en/legal/copytrade/.
The following terms are trademarks of Lenovo in the United States, other countries, or both:
Lenovo®
ThinkSystem®
The following terms are trademarks of other companies:
Intel®, the Intel logo and Xeon® are trademarks of Intel Corporation or its subsidiaries.
Linux® is the trademark of Linus Torvalds in the U.S. and other countries.
Other company, product, or service names may be trademarks or service marks of others.
Configure and Buy
Please select a locale
Full Change History
Course Detail
Employees Only Content
The content in this document with a is only visible to employees who are logged in. Logon using your Lenovo ITcode and password via Lenovo single-signon (SSO).
The author of the document has determined that this content is classified as Lenovo Internal and should not be normally be made available to people who are not employees or contractors. This includes partners, customers, and competitors. The reasons may vary and you should reach out to the authors of the document for clarification, if needed. Be cautious about sharing this content with others as it may contain sensitive information.
Any visitor to the Lenovo Press web site who is not logged on will not be able to see this employee-only content. This content is excluded from search engine indexes and will not appear in any search results.
For all users, including logged-in employees, this employee-only content does not appear in the PDF version of this document.
This functionality is cookie based. The web site will normally remember your login state between browser sessions, however, if you clear cookies at the end of a session or work in an Incognito/Private browser window, then you will need to log in each time.
If you have any questions about this feature of the Lenovo Press web, please email David Watts at dwatts@lenovo.com.





