

Top
Published
10 Oct 2025Form Number
LP2286PDF size
43 pages, 6.3 MBSubscribed to LP2286.
Thank you for your feedback.
Table of Contents
Abstract
Lenovo Hybrid AI 289 is a platform that enables enterprises of all sizes to quickly deploy hybrid AI factory infrastructure, supporting Enterprise AI use cases as either a new, greenfield environment or an extension of their existing IT infrastructure. The offering is based on the NVIDIA 2-8-9 configuration— 2x CPUs, 8x GPUs, and 9x network adapters — and is ideally suited for model training and large-scale inference use cases.
Lenovo Hybrid AI 289 combines market leading Lenovo ThinkSystem GPU-rich servers with NVIDIA GPUs, NVIDIA Spectrum X networking and enables the use of the NVIDIA AI Enterprise software stack with NVIDIA Blueprints. The Hybrid AI 289 platform is endorsed by NVIDIA for Infrastructure Configuration, Networking Logic, and Software, and is based on the NVIDIA Enterprise Reference Architecture for the NVIDIA HGX H200/B200 and Spectrum-X Networking Platform.
This guide is for sales architects, customers and partners who want to quickly stand up a validated AI infrastructure solution.
Introduction
The evolution from Generative AI to Agentic AI has revolutionized the landscape of business and enterprise operations globally. By leveraging the capabilities of intelligent agents, companies can now streamline processes, enhance efficiency, and maintain a competitive edge.
These AI agents are adept at handling routine tasks, allowing skilled employees to focus on strategic initiatives and areas where their expertise truly adds value. This symbiotic relationship between AI agents and human employees fosters a collaborative environment that drives innovation and success.
Enterprises must proactively identify opportunities where AI agents can be integrated to support their operations, ensuring they remain agile and effective in an ever-evolving market. This new foundation of AI-driven optimization not only boosts productivity but also empowers employees to contribute more meaningfully to the organization's vision and goals.
Lenovo Hybrid AI 289 is a platform that enables enterprises of all sizes to quickly deploy hybrid AI factory infrastructure, supporting Enterprise AI use cases as either a new, greenfield environment or an extension of their existing IT infrastructure.

Figure 1. Lenovo Hybrid AI 289 platform overview
The offering is based on the NVIDIA 2-8-9 HGX configuration— 2x CPUs, 8x GPUs, and 9x network adapters — and is ideally suited for model training, fine-tuning, and large-scale inference use cases. It combines market leading Lenovo ThinkSystem GPU-rich servers with NVIDIA Hopper GPUs, NVIDIA Spectrum X networking and enables the use of the NVIDIA AI Enterprise software stack with NVIDIA Blueprints.
Following the principle of From Exascale to EveryScale™, Lenovo, widely recognized as a leader in High Performance Computing, leverages its expertise and capabilities from Supercomputing to create tailored enterprise-class hybrid AI factories.
Ideally utilizing Lenovo EveryScale Infrastructure (LESI) it comes with the EveryScale Solution verified interoperability for the tested Best Recipe hardware and software stack. Additionally, EveryScale allows Lenovo Hybrid AI platform deployments to be delivered as fully pre-built, rack-integrated systems that are ready for immediate use.
Use Cases
The 32 petaflops of processing power per NVIDIA HGX H200 8-GPU baseboard and the additional bandwidth in the East-West compute network makes the 289 platform best suited for LLM fine-tuning and training. The Lenovo Hybrid AI 289 platform supports up to 32 scalable units, totaling 128 AI compute nodes and 1,024 GPUs, with high network bandwidth—ideal for even the most demanding AI training workloads. LLM training times that may have taken weeks with previous AI infrastructures can be reduced to a matter of days using the 289 platform.
Although inference and large-scale RAG applications can be implemented on the 289 platform, medium-sized LLMs with 58B parameters at 16-bit precision can fit on a single H200/B200 SXM GPU, meaning that the added network bandwidth in 289 is unnecessary in medium inference cases. Furthermore, by reducing parameter precision to 4 bits, 4 58B parameter models can fit on one SXM GPU. If per-GPU or per-node inference will be the main use case of your enterprise, consider the Lenovo Hybrid AI 285 platform.
As some of the leading open-source LLMs such as DeepSeek-R1-0528 and Llama 4 Maverick have hundreds of billions of parameters as opposed to tens of billions, inference is becoming more compute intensive. The addition of LLM tooling and RAG only adds to the compute needs of large-scale AI systems. Note that at the time of this document’s writing Kimi-K2 is the largest and most performant open-source model, which has 1 trillion parameters at FP8 precision. At that size, Kimi-K2 consumes the entire memory of one HGX H200 8-GPU board, or it can be quantized to 4-bit precision to fit two Kimi-K2 models on one HGX H200. It’s reasonable to expect model sizes to grow in the future, requiring more and more compute. Consider whether your enterprise values model accuracy, speed, and/or concurrency when performing model and platform selection. If utilizing the most powerful LLMs for inference and providing those models access to large amounts of data for RAG and tooling, 289 may provide the compute needed, or the 285 platform with B200 GPUs would be required to run per-node inference.
To discuss your enterprise’s exact needs and decide on the optimal solution for your use case, please contact your Lenovo representative.
Overview
The Lenovo 289 Platform comes in 3 main configurations: 3 Scalable Units, 8 Scalable Units, and 32 Scalable units. All 3 configurations provide 100G or 200G connectivity to storage, and 200G connectivity to the enterprise network and support servers.
See figures below for a sizing overview.
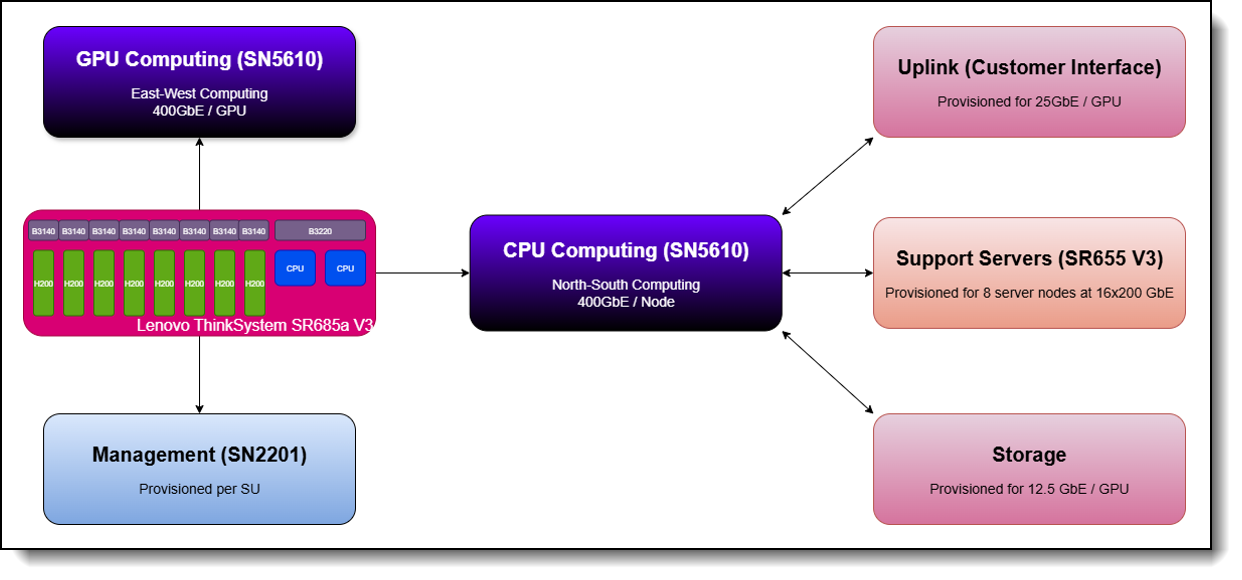
Figure 2. Lenovo Hybrid AI 289 Converged Network Architecture Diagram
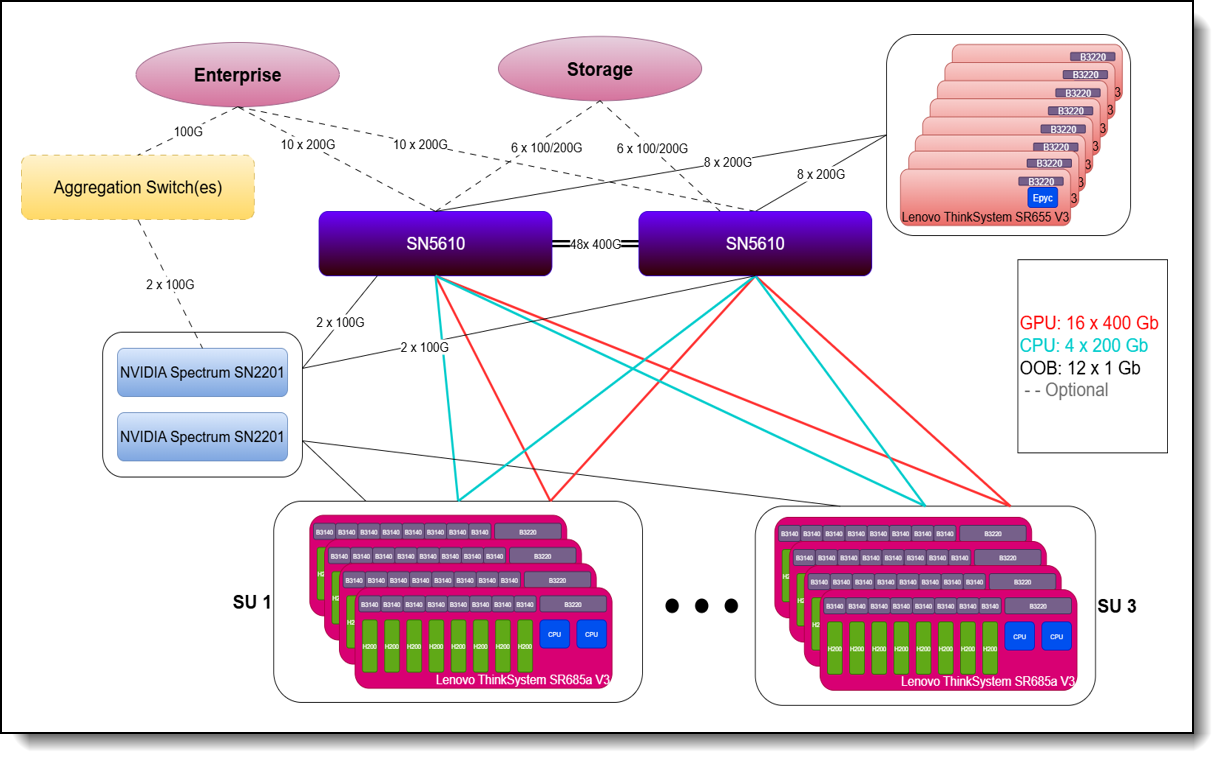
Figure 3. Lenovo Hybrid AI 289 platform with 3 Scalable Units
It can be deployed even for larger sizes with 8 Scalable Units with 32 Servers and 256 GPUs by breaking out the network using four more SN5610s to create a dedicated E/W network for GPU-to-GPU communication.
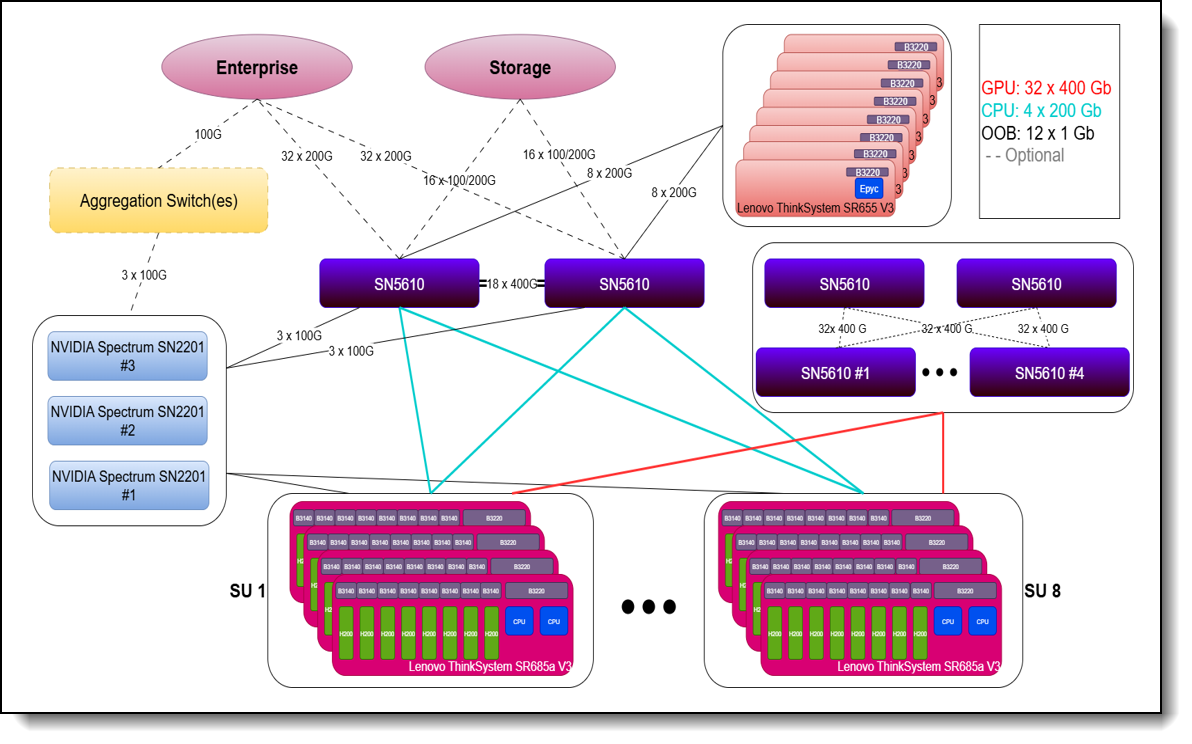
Figure 4. Lenovo Hybrid AI 289 platform with 8 Scalable Units
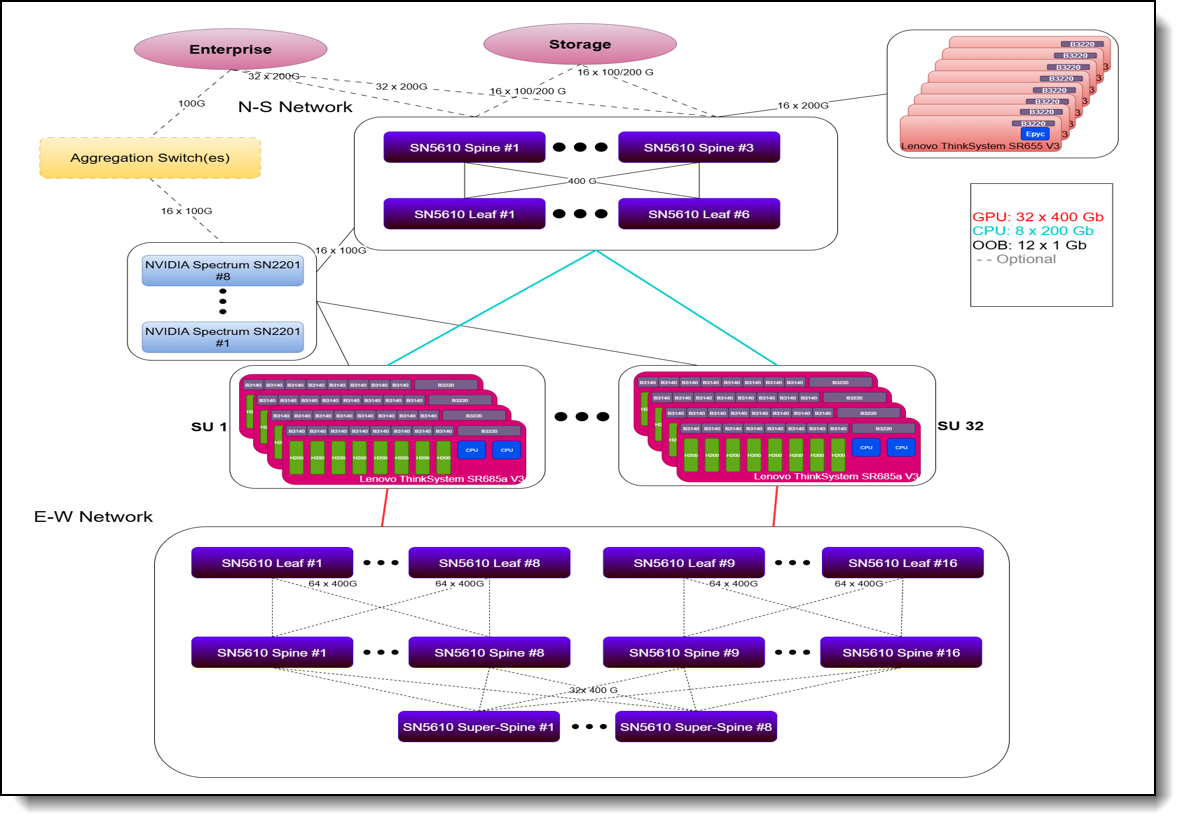
Figure 5. Lenovo Hybrid AI 289 platform with 32 Scalable Units
Note: The implementation of a Super-Spine layer enables ease of scaling beyond 32 SU’s. If there is no intention of scaling, the network can be implemented without a Super-Spine layer, which only requires 24 switches as opposed to 40 and leads to reduced costs.
Low Level Architecture Details
Properly understanding and constructing the network fabric is crucial to getting maximum performance and efficiency out of the 289 platform. The table below shows what resources are needed as the system scales up in a per-SU basis. The high-level architectures in the previous section show the main components and connections between them, while the table below describes exact number of connections between layers of the network.
To maximally utilize the network bandwidth and compute resources when going above 3 SUs, the compute network topology should follow a rail-optimized configuration. In a rail-optimized configuration, the ith NIC on every node is connected to the same switch, which allows the system to take advantage of the NVSwitch technology present on every HGX GPU to reduce interference between flows. This works because on every HGX system, the data can be quickly moved to a GPU connected to the same switch through the NICs as the destination GPU. Below we will go into more detail on the network fabric for these configurations, and permutations can be made upon the specified fabrics when deploying a different amount of SU’s by consulting the above table. Note that for the cases where the leaf switch count does not evenly divide 8, rails will have to connect to different NICs/GPUs depending on the node.
In a rail-optimized configuration, a rail refers to the group of NICs/GPUs that are all connected to the same switch. So, to describe the fabric, we will map NICs/GPUs 1 through 8 to one of the available switches in that architecture.
8 SU GPU Network Fabric
32 SU GPU Network Fabric
Recall from the earlier table that above 24 SU’s, a Super-Spine layer can be introduced. In the case where a Super Spine is introduced, we will break the SU’s into two groups: SU’s 1-16 and SU’s 17-32. Note that the leaf and spine layers are fully connected from 1 to 8 and 9 to 16, and the Spine and Super-Spine layers are all fully connected.
1-16
For this group of SU’s, the GPU/NIC to rail connection is i-to-i, meaning that GPU 1 is connected to rail 1, GPU 2 is connected to rail 2, etc.
| Rail | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| GPU / NIC | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
17-32
For this group of SU’s, the GPU/NIC to rail connection is i-to-i + 8
| Rail | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 |
|---|---|---|---|---|---|---|---|---|
| GPU / NIC | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
Out-Of-Band (OOB) Management
On a per-node basis there are 2 OOB Management connections, one to the B3220 DPU RJ45 Connector and one to the BMC. While this is the recommended fabric for OOB Management, all B3140 SuperNICs also have RJ45 Connectors that could be added to the management fabric.
Components
The main hardware components of Lenovo Hybrid AI platforms are Compute nodes and the Networking infrastructure. As an integrated solution they can come together in either a Lenovo EveryScale Rack (Machine Type 1410) or Lenovo EveryScale Client Site Integration Kit (Machine Type 7X74).
Topics in this section:
AI Compute Nodes and Service Nodes
The Lenovo Hybrid AI 289 platform provides three possible GPU server nodes and service nodes to use as the AI Compute Node:
- Lenovo ThinkSystem SR680a V3
- Lenovo ThinkSystem SR685a V3
- Lenovo ThinkSystem SR780a V3 Water Cooled
- Service Nodes – SR655 V3
- Configuration
Lenovo ThinkSystem SR680a V3
The AI Compute Node leverages the SR680a V3
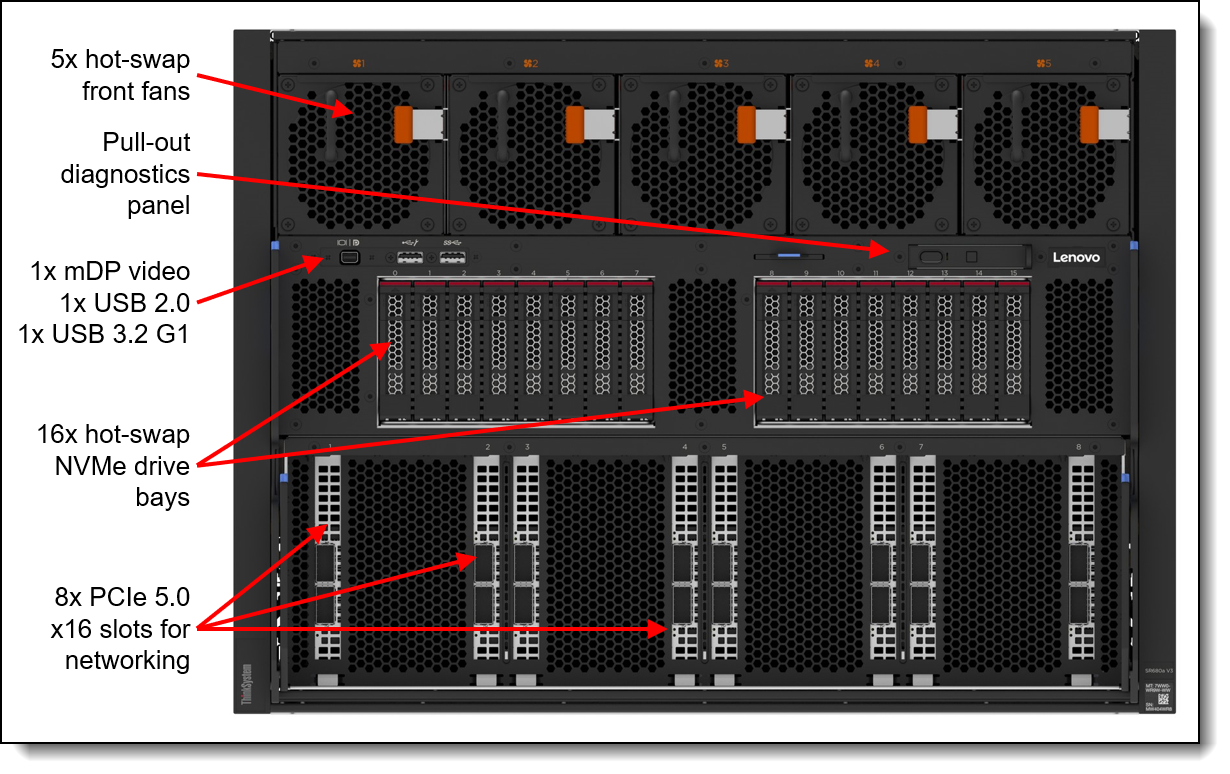
Figure 6. List of components and connectors in Lenovo ThinkSystem SR680a V3
The SR680a V3 is a 2-socket 5th Gen AMD EPYC 9005 server that supports the NVIDIA HGX H200 system with 9 network adapters in a 8U rack server chassis.
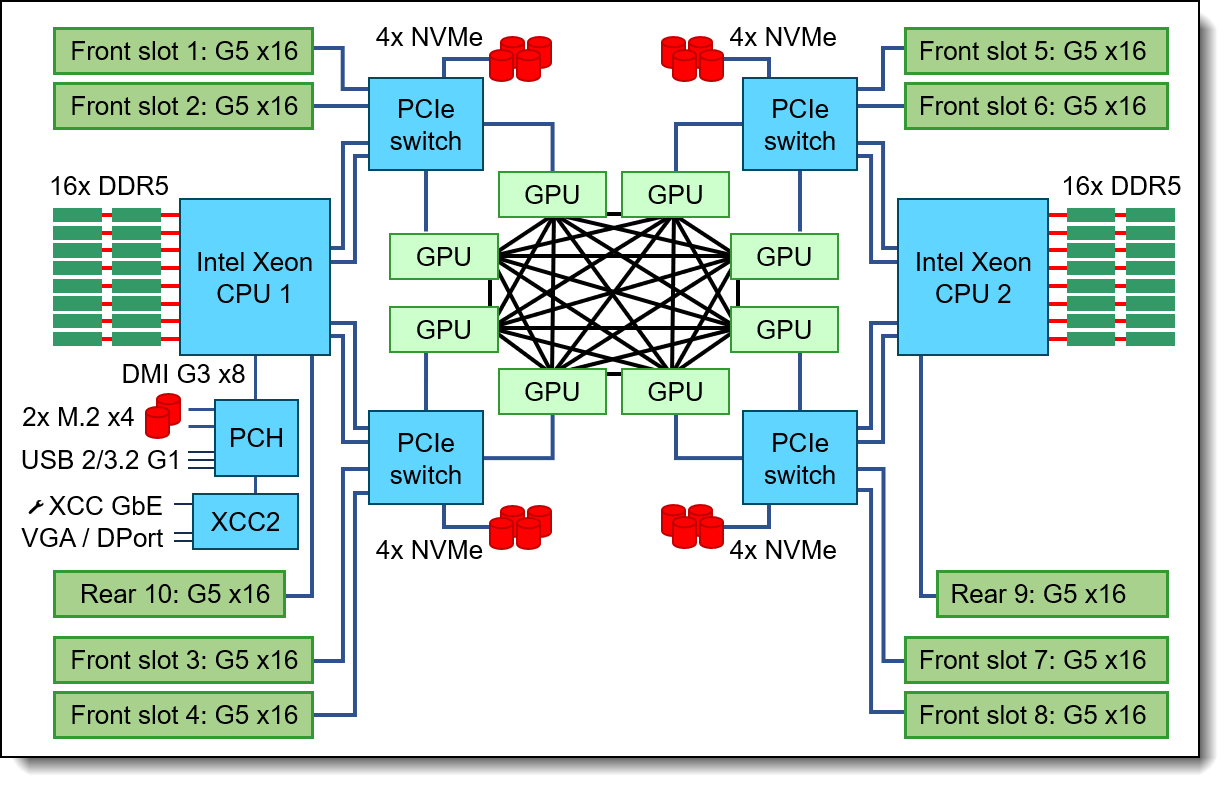
Figure 7. SR680a V3 AI Compute Node Block Diagram
For the CPU, the AI Compute node is configured with two Intel Xeon Platinum 8570 64 Core 2.4 GHz processors with an all-core boost frequency of 4GHz. The Xeon Platinum provides 56 cores and 112 threads for each of the Multi Instance GPUs (MIGs). With a 300 MB L3 Cache, this processor excels at accessing frequently used data compared to its AMD EPYC 9535 counterpart, which only has a 256 MB L3 Cache.
Lenovo ThinkSystem SR685a V3
The AI Compute Node leverages the SR685a V3
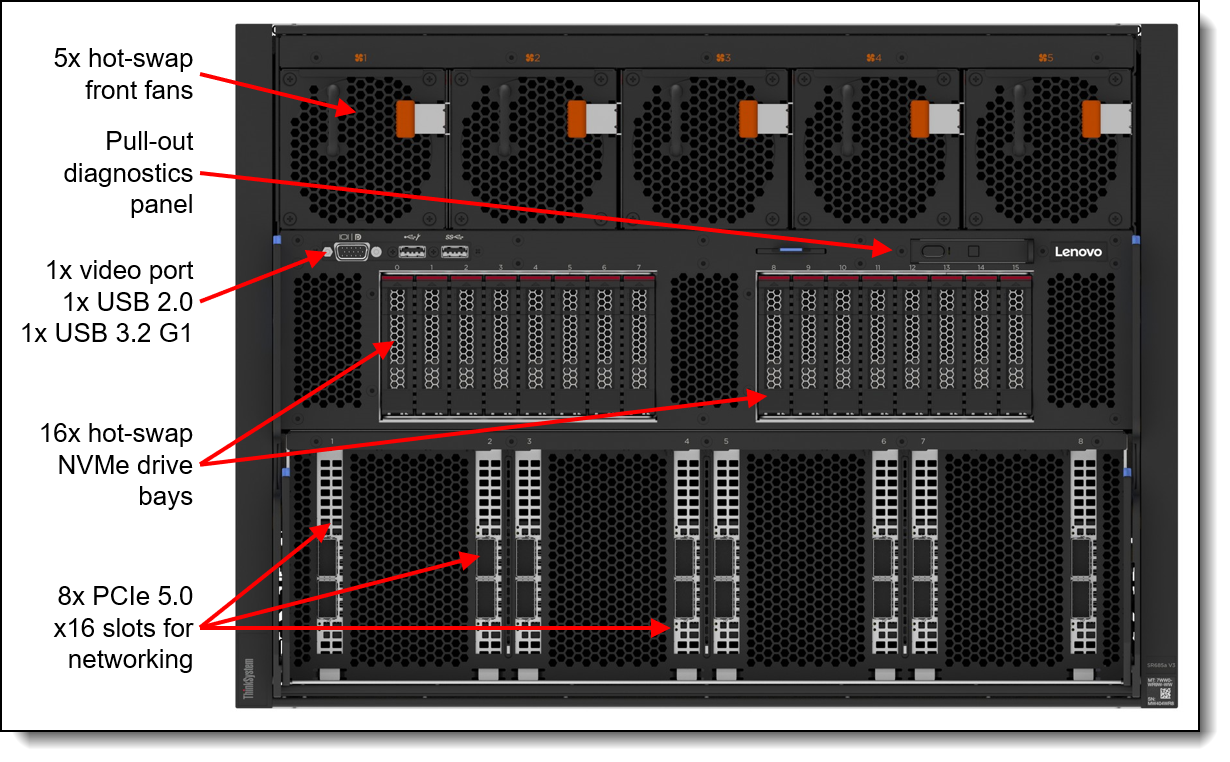
Figure 8. List of components and connectors in Lenovo ThinkSystem SR685a V3
The SR685a V3 is a 2-socket 5th Gen AMD EPYC 9005 server that supports the NVIDIA HGX H200 system with 9 network adapters in a 8U rack server chassis.
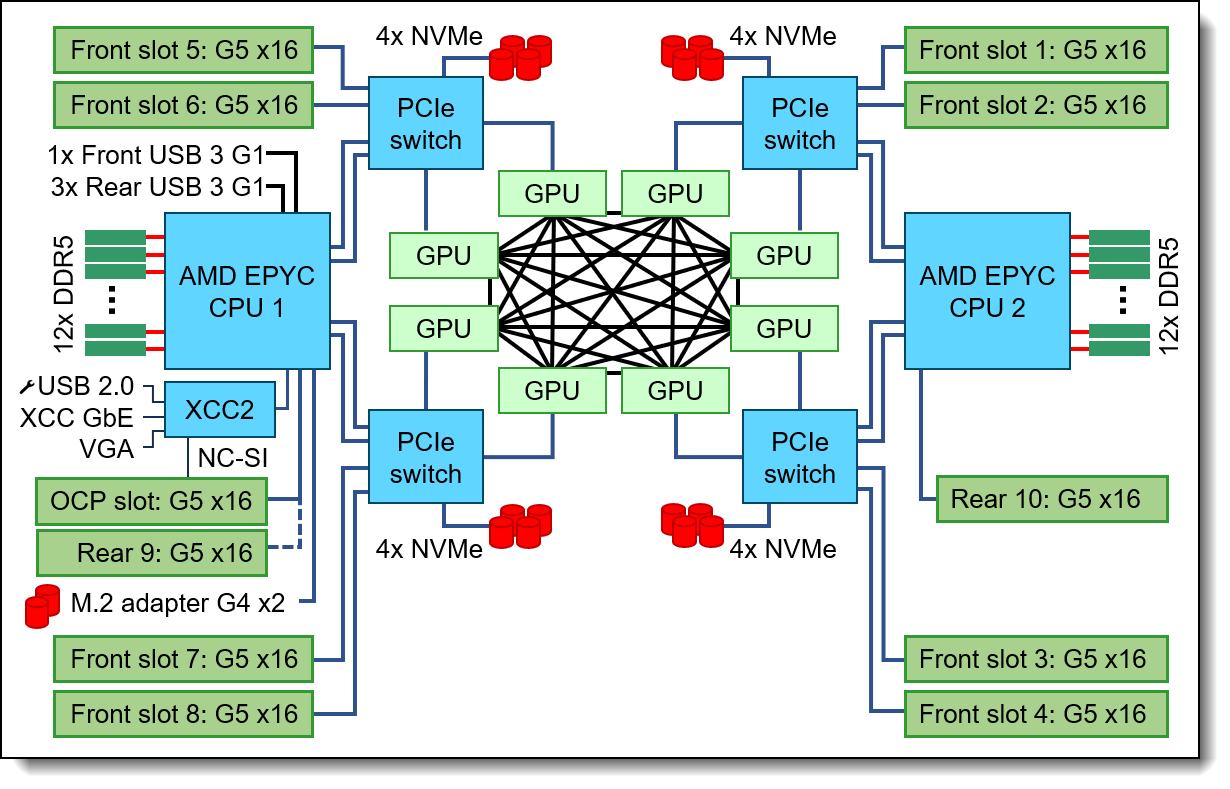
Figure 9. SR680a V3 AI Compute Node Block Diagram
For the CPU, this AI Compute node is configured with two AMD EPYC 9535 64 Core 2.4 GHz processors with an all-core boost frequency of 3.5GHz. Besides providing consistently more than 2GHz frequency this ensures that with 7 Multi Instance GPUs (MIG) on 8 physical GPUs there are 2 Cores available per MIG plus a few additional Cores for Operating System and other operations. With 12 Memory Channels per processor socket the AMD based server provides superior Memory bandwidth versus computing Intel-based platforms ensuring highest performance. Leveraging 64GB 6400MHz Memory DIMMs for a total of 1.5TB of main memory providing 192GB memory per GPU or a minimum of 1.5X the HGX H200 GPU memory.
Lenovo ThinkSystem SR780a V3 Water Cooled
The AI Compute Node leverages the SR780a V3
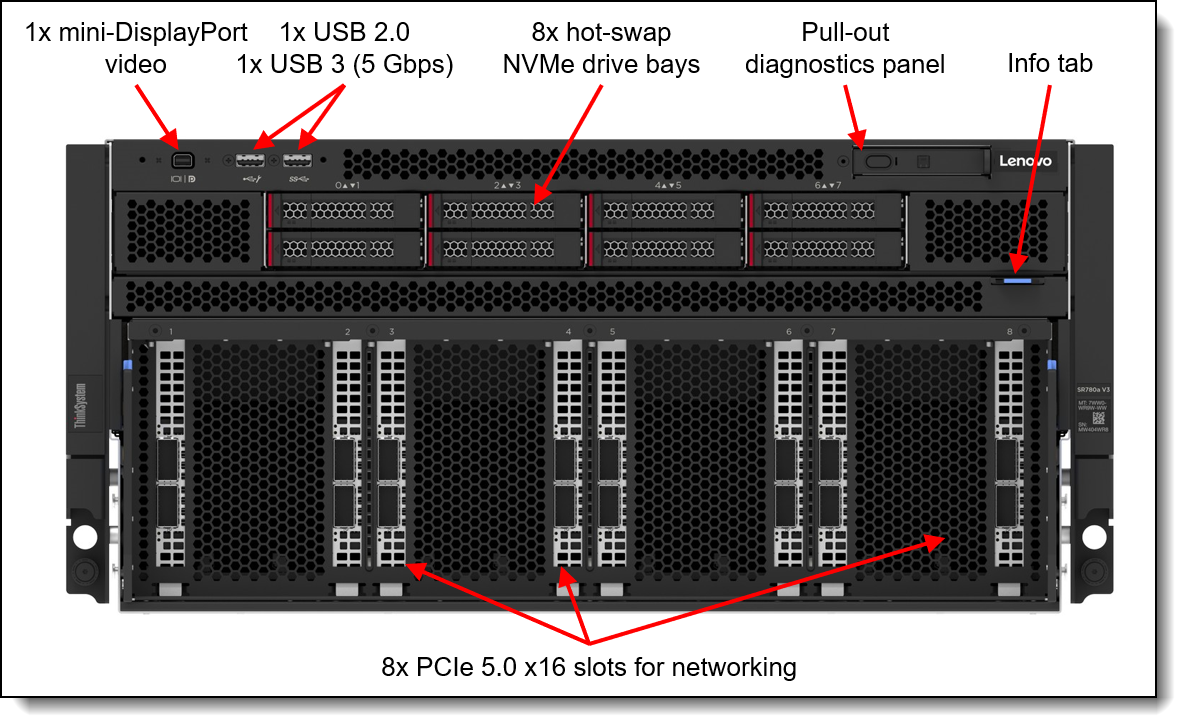
Figure 10. List of components and connectors in Lenovo ThinkSystem SR780a V3
The SR780a V3 is a liquid-cooled 2-socket 5th Gen AMD EPYC 9005 server that supports the NVIDIA HGX H200 system with 9 network adapters in a 5U rack server chassis.
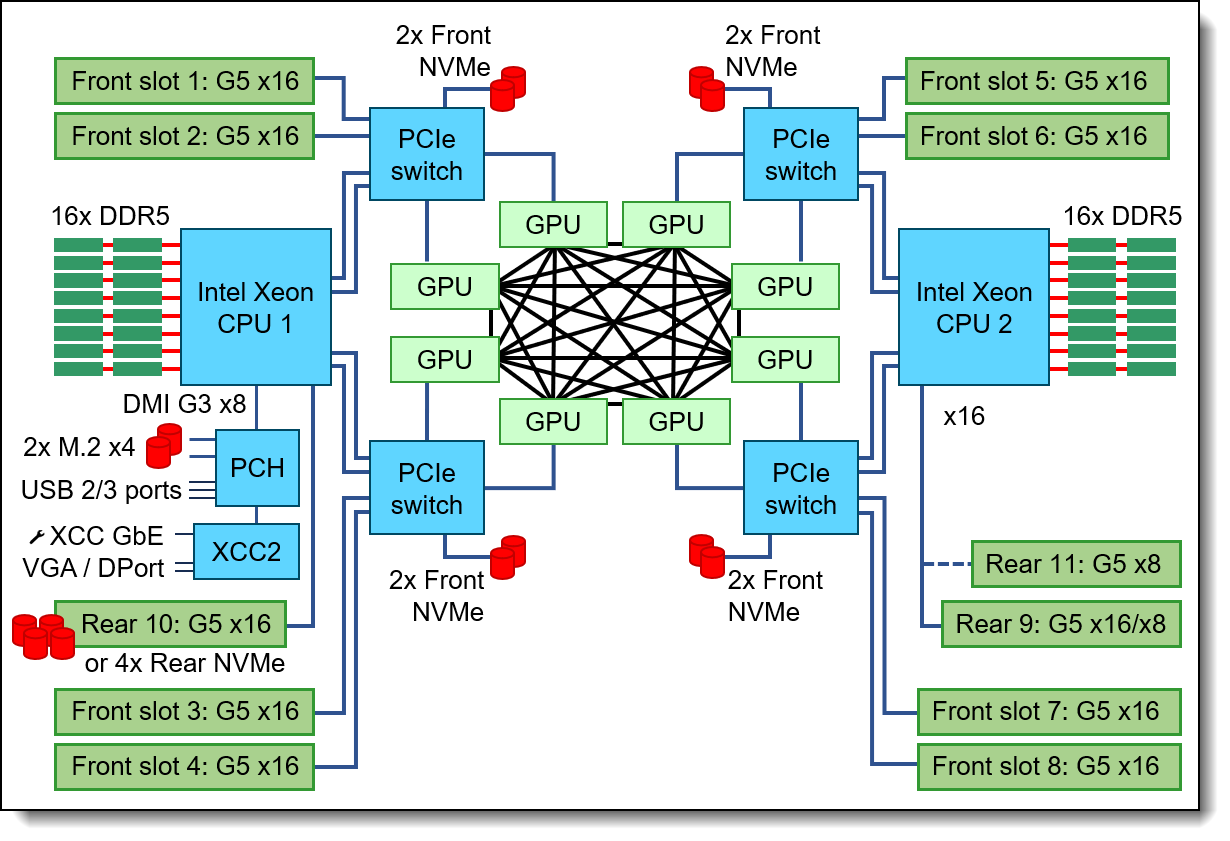
Figure 11. AI Compute Node Block Diagram for the SR780a V3
For the CPU, the AI Compute node is configured with two Intel Xeon Platinum 8558 48C 2.7GHz processors with an all-core boost frequency of 4GHz (Same as the SR680a V3 CPU).
- Ports
On all 3 servers (SR680a V3, SR685a V3, and SR780a V3), front slots 1 through 8 are connected to NICs 1 through 8 for the B3140 SuperNIC. The B3220 is present on the Rear 9 slot.
- Ethernet
For Converged (North-South) Network an Ethernet adapter with redundant 200Gb/s connections provides ample bandwidth to storage, service nodes and the Enterprise network. The NVIDIA BlueField-3 B3220 P-Series FHHL DPU provides the two 200Gb/s Ethernet ports, a 1Gb/s Management board and a 16-Core ARM chip enabling Cloud Orchestration, Storage Acceleration, Secure Infrastructure and Tenant Networking.
The Ethernet adapters for the Compute (East-West) Network are directly connected to the GPUs via PCIe switches minimizing latency and enabling NVIDIA GPUDirect and GPUDirect Storage operation. For pure Inference workload they are optional, but for training and fine-tuning operation they should provide at least 200Gb/s per GPU.
By using the NVIDIA BlueField-3 B3140H E-Series HHHL DPU or alternatively a ConnectX8 400Gbit Ethernet adapter in combination with NVIDIA Spectrum 4 networking the East-West traffic can utilize Spectrum X operation.
- Storage
The system is completed by local storage with two 960GB Read Intensive M.2 in RAID1 configuration for the operating system and four 3.84TB Read Intensive E3.S drives for local application data.
- GPU Selection
NVIDIA HGX H200
The NVIDIA HGX H200 is a powerful GPU designed to accelerate both generative AI and high-performance computing (HPC) workloads. It boasts a massive 141GB of HBM3e memory, which is nearly double the capacity of its predecessor, the H100. This increased memory, coupled with a 4.8 terabytes per second (TB/s) memory bandwidth, enables the HGX H200 to handle larger and more complex AI models, like large language models (LLMs), with significantly improved performance. The HGX H200 is built with maximum power and scalability with up to 4 Petaflops of FP8 performance. The HGX H200 uses 8 SXM based GPUs that are directly connected rather than PCIe which allows for faster communication with 900 GB/s bandwidth.
NVIDIA HGX B200
The NVIDIA HGX B200 is designed to supercharge AI and High Performance (HPC) workloads. This GPU is built off the Blackwell architecture, with 180GB of HBM3e memory per GPU. The HGX B200 has 1.8 terabytes per second (TB/s) of GPU-GPU interconnection bandwidth which ensures rapid data transfer and highly efficient processing. Additionally, in the Lenovo ThinkSystem SR780a the HGX B200 uses an advanced liquid-cooling system to effectively dissipate heat and reduce data center electricity costs.
Service Nodes – SR655 V3
The AI Service node leverages the SR655 V3
When deploying beyond two AI Compute nodes additional Service nodes are needed to manage the overall AI cluster environment.
Two Management Nodes provide a high-availability for the System Management and Monitoring provided through NVIDIA Base Command Manager (BMC) as described further in the AI Software Stack chapter.
For the Container operations three Scheduling Nodes build the Kubernetes control plane providing redundant operations and quorum capability.
Two SLURM Nodes are provided to facilitate training workloads. If only Kubernetes is intended to be used, these nodes can be converted into additional Kubernetes Scheduling nodes or removed altogether.
Finally, a Login Node is provided for cluster access and management.

Figure 12. Lenovo ThinkSystem SR655 V3
The Lenovo ThinkSystem SR655 V3 is an optimal choice for a homogeneous host environment, featuring a single socket AMD EPYC 9335 with 32 cores operating at 3.0 GHz base with an all-core boost frequency of 4.0GHz. The system is fully equipped with twelve 32GB 6400MHz Memory DIMMs, two 960GB Read Intensive M.2 drives in RAID1 configuration for the operating system, and two 3.84TB Read Intensive U.2 drives for local data storage. Additionally, it includes a NVIDIA BlueField-3 B3220L E-Series FHHL DPU adapter to connect the Service Nodes to the Converged Network.
Configuration
The following table lists the configuration of a single Service Node.
Networking
The default setup of the Lenovo Hybrid AI 289 platform leverages NVIDIA Networking with the NVIDIA Spectrum-4 SN5610 for the Converged and Compute Network and the NVIDIA SN2201 for the Management Network.
NVIDIA SN5600 / SN5610
The SN5610 smart-leaf, spine, and super-spine switch offers 64 ports of 800GbE in a dense 2U form factor. The SN5610 is ideal for NVIDIA Spectrum-X deployments and enables both standard leaf/spine designs with top-of-rack (ToR) switches as well as end-of-row (EoR) topologies. The SN5610 offers diverse connectivity in combinations of 1 to 800GbE and boasts an industry-leading total throughput of 51.2Tb/s.

Figure 13. NVIDIA SN5610 Switch
The Converged (North-South) Network handles storage and in-band management, linking the Enterprise IT environment to the Agentic AI platform. Built on Ethernet with RDMA over Converged Ethernet (RoCE), it supports current and new cloud and storage services as outlined in the AI Compute node configuration.
The Converged Network connects to the Enterprise IT network with up to 40 Ethernet connections at 200Gb/s for up to five Scalable Units (SU) or 64 Ethernet connections at 200Gb/s for up to eight SUs. This setup guarantees an ideal bandwidth of 25GB/s per GPU.
In addition to providing access to the AI agents and functions of the AI platform, this connection is utilized for all data ingestion from the Enterprise IT data during indexing and embedding into the Retrieval-Augmented Generation (RAG) process. It is also used for data retrieval during AI operations.
The Compute (East-West) Network facilitates application communication between the GPUs across the Compute nodes of the AI platform. It is designed to achieve minimal latency and maximal performance using a rail-optimized, fully non-blocking fat tree topology with NVIDIA Spectrum-X.
Spectrum X reduces latency and increases bandwidth for Ethernet by using advanced functionality that splits network packets, tags them, and allows the switch to balance them across network lanes. The receiving node then reassembles the packets regardless of the order they were received in. This process helps avoid hash collusion and congestion, which often lead to suboptimal performance in low-entropy networks.
Tip: In a pure Inference use case, the Compute Network is typically not necessary, but for training and fine-tuning operations it is a crucial component of the solution.
For configurations of up to five Scalable Units, the Compute and Converged Network are integrated utilizing the same switches. When deploying more than five units, it is necessary to separate the fabric.
The following table lists the configuration of the NVIDIA Spectrum-4 SN5610 (link to BOM)
| Part Number | Description | Quantity |
|---|---|---|
| NVIDIA SKU: 920-9N42F-00RI-3C1 | NVIDIA SN5610 | 2 |
The SN5610 must be purchased directly through NVIDIA. A Lenovo Part Number will be added to this document once created.
NVIDIA Spectrum SN2201
The SN2201 is ideal as an out-of-band (OOB) management switch or as a ToR switch connecting up to 48 1G Base-T host ports with non-blocking 100GbE spine uplinks. Featuring highly advanced hardware and software along with ASIC-level telemetry and a 16 megabyte (MB) fully shared buffer, the SN2201 delivers unique and innovative features to 1G switching.

Figure 14. NVIDIA Spectrum SN2201
The Out-of-Band (Management) Network encompasses all AI Compute node and BlueField-3 DPU base management controllers (BMC) as well as the network infrastructure management.
The following table lists the configuration of the NVIDIA Spectrum SN2201.
Lenovo EveryScale Solution
The Server and Networking components and Operating System can come together as a Lenovo EveryScale Solution. It is a framework for designing, manufacturing, integrating and delivering data center solutions, with a focus on High Performance Computing (HPC), Technical Computing, and Artificial Intelligence (AI) environments.
Lenovo EveryScale provides Best Recipe guides to warrant interoperability of hardware, software and firmware among a variety of Lenovo and third-party components.
Addressing specific needs in the data center, while also optimizing the solution design for application performance, requires a significant level of effort and expertise. Customers need to choose the right hardware and software components, solve interoperability challenges across multiple vendors, and determine optimal firmware levels across the entire solution to ensure operational excellence, maximize performance, and drive best total cost of ownership.
Lenovo EveryScale reduces this burden on the customer by pre-testing and validating a large selection of Lenovo and third-party components, to create a “Best Recipe” of components and firmware levels that work seamlessly together as a solution. From this testing, customers can be confident that such a best practice solution will run optimally for their workloads, tailored to the client’s needs.
In addition to interoperability testing, Lenovo EveryScale hardware is pre-integrated, pre-cabled, pre-loaded with the best recipe and optionally an OS-image and tested at the rack level in manufacturing, to ensure a reliable delivery and minimize installation time in the customer data center.
Configurations
Configurations
The 2-8-9 platform can come in 3 main variants: 3 Scalable Units, 8 Scalable Units, and 32 Scalable Units, depending on the use case. Each node requires at a minimum 8,555 W, so 4 nodes in a rack would require ~34,000W. If your rack cannot support these power requirements, the nodes can be split into two racks per SU
Power requirements:
- SR680a: 8996 W
- SR685a: 8978.2 W
- SR780a: 8555 W
The networking decision depends on whether the platform is designed to support up to three, eight, or thirty-two Scalable Units in total. Subsequently, the solution can be expanded seamlessly without downtime by incorporating additional Scalable Units, ultimately reaching a total of eight or 32 as needed.
The following describe the three and eight Scalable Units deployments:

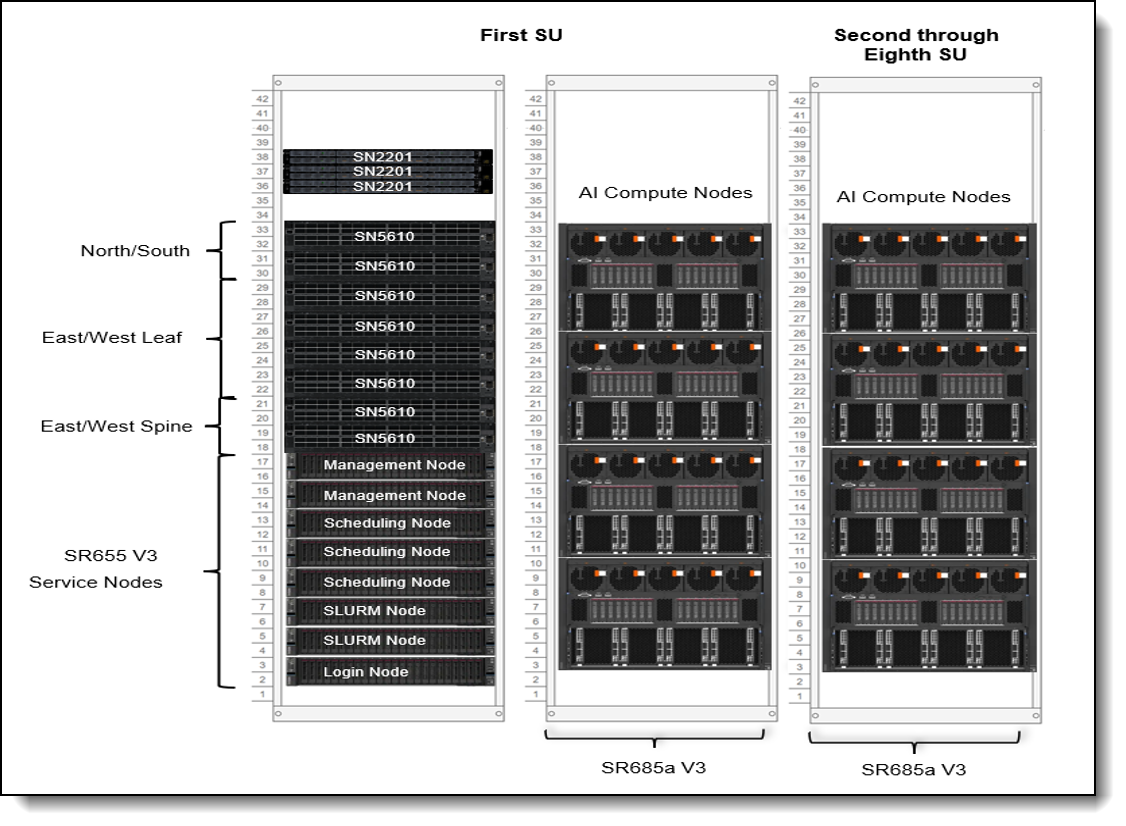
Scalability
Custom Deployment
For high-end scenarios requiring more than eight scalable units, the network can be custom designed to any required size. Lenovo will develop a fully bespoke solution tailored to match the workflow and workload requirements in that case.
Note: For the 3SU configuration, Direct Attach Copper (DAC) cabling can be used to reduce cost while maintaining the necessary bandwidth. This cabling will reduce costs when compared to using fiber-optic cabling.
AI Software Stack
Deploying AI to production involves implementing multiple layers of software. The process begins with the system management and operating system of the compute nodes, progresses through a workload or container scheduling and cluster management environment, and culminates in the AI software stack that enables delivering AI agents to users.
Please refer to the Lenovo Hybrid AI Software Platform for more details however the stack has been listed below.
In the following sections, we take a deeper dive into the software elements:
Lenovo XClarity One
Lenovo XClarity One is a management-as-a-service offering for hybrid-cloud management of on-premises data-center assets from Lenovo. Local management hubs can be installed across multiple sites to collect inventory, incidents, and service data, and to provision resources, creating a bridge between devices and the XClarity One portal. The XClarity One portal provides a modern, intuitive interface that centralizes IT orchestration, deployment, automation, and support from edge to cloud, with enhanced visibility into infrastructure performance, usage metering, and analytics.
The following functions are supported by XClarity One:
- XClarity One dashboard
- Firmware management
- Security
- User Management
- Hardware Monitoring
Linux Operating System
The AI Compute nodes are typically deployed with Ubuntu Server LTS Edition which is a Linux distribution that is maintained for a minimum of 5 years by Canonical as standard, thereby reducing the need for major upgrades. All of the software in this Reference Architecture is compatible and validated with Ubuntu Server LTS edition. Customers should also consider purchasing additional support for Ubuntu Server LTS using the Ubuntu Pro Edition upgrade. Lenovo Hybrid AI platforms also support Red Hat Enterprise Linux (RHEL) which is distributed as part of a paid licensed model that automatically comes with support. Ultimately, the choice of Linux distributions is one the customer needs to make based on their familiarity with Linux and their ability to support an unlicensed distribution v.s. a licensed distribution with contractual support.
Base Command Manager and Container
Base Command Manager (BCM) provisions the AI environment, incorporating the components such as the Operating System, Vanilla Kubernetes (K8S), GPU Operator, and Network Operator to manage the AI workloads. BCM Supports 3 types of network topologies depending on how the user wants nodes to be accessed.
BCM orchestration capabilities with Kubernetes are a key feature. The software simplifies the lifecycle management of a Kubernetes cluster, from initial setup to ongoing operations. It automates the provisioning of compute nodes, integrates crucial components like the NVIDIA GPU Operator to expose GPUs to Kubernetes, and facilitates the scheduling of jobs on the cluster. This allows for fine-grained control over resource allocation and enables features like Multi-Instance GPU (MIG), which can partition a single physical GPU into multiple smaller, isolated instances. BCM provides a unified management platform for both the physical hardware and the container orchestration layer.
Kubernetes Layer
Kubernetes is the leading AI container deployment and workload management tool in the market, which can be used for edge and centralized data center deployments.
“Vanilla Kubernetes” (an upstream, open-source build) is the recommended version of Kubernetes that has been validated as a part of this software stack and deployed by Base Command Manager. Canonical Kubernetes offers additional functionality beyond Vanilla, and is used across industries for mission critical workloads, offering up to 12 years of security for those customers who cannot, or choose not to upgrade their Kubernetes versions.
Note - when choosing Red Hat for the Linux Operating System, Red Hat OpenShift should be deployed as the container orchestration layer.
Data and AI Applications
Canonical’s Ubuntu Pro includes a portfolio of open source applications in the data and AI space including leading projects for ML space with KubeFlow and MLFlow, big data and database with Spark, Kafka, PostgreSQL, Mongo and others. Ubuntu Pro enables customers on their open source AI journey to simplify deployment and maintenance of these applications and provides security maintenance.
NVIDIA AI Enterprise
The Lenovo Hybrid AI platform is designed for NVIDIA AI Enterprise, which is a comprehensive suite of artificial intelligence and data analytics software designed for optimized development and deployment in enterprise settings.
Figure 17. NVIDIA AI Enterprise software stack
NVIDIA AI Enterprise includes workload and infrastructure management software known as Base Command Manager. This software provisions the AI environment, incorporating the components such as the Operating System, Kubernetes (K8S), GPU Operator, and Network Operator to manage the AI workloads.
Additionally, NVIDIA AI Enterprise provides access to ready-to-use open-sourced containers and frameworks from NVIDIA like NVIDIA NeMo, NVIDIA RAPIDS, NVIDIA TAO Toolkit, NVIDIA TensorRT and NVIDIA Triton Inference Server.
- NVIDIA NeMo is an end-to-end framework for building, customizing, and deploying enterprise-grade generative AI models; NeMo lets organizations easily customize pretrained foundation models from NVIDIA and select community models for domain-specific use cases.
- NVIDIA RAPIDS is an open-source suite of GPU-accelerated data science and AI libraries with APIs that match the most popular open-source data tools. It accelerates performance by orders of magnitude at scale across data pipelines.
- NVIDIA TAO Toolkit simplifies model creation, training, and optimization with TensorFlow and PyTorch and it enables creating custom, production-ready AI models by fine-tuning NVIDIA pretrained models and large training datasets.
- NVIDIA TensorRT, an SDK for high-performance deep learning inference, includes a deep learning inference optimizer and runtime that delivers low latency and high throughput for inference applications. TensorRT is built on the NVIDIA CUDA parallel programming model and enables you to optimize inference using techniques such as quantization, layer and tensor fusion, kernel tuning, and others on NVIDIA GPUs. https://developer.nvidia.com/tensorrt-getting-started
- NVIDIA TensorRT-LLM is an open-source library that accelerates and optimizes inference performance of the latest large language models (LLMs). TensorRT-LLM wraps TensorRT’s deep learning compiler and includes optimized kernels from FasterTransformer, pre- and post-processing, and multi-GPU and multi-node communication. https://developer.nvidia.com/tensorrt
- NVIDIA Triton Inference Server optimizes the deployment of AI models at scale and in production for both neural networks and tree-based models on GPUs.
It also provides full access to the NVIDIA NGC catalogue, a collection of tested enterprise software, services and tools supporting end-to-end AI and digital twin workflows and can be integrated with MLOps platforms such as ClearML, Domino Data Lab, Run:ai, UbiOps, and Weights & Biases.
Finally, NVIDIA AI Enterprise introduced NVIDIA Inference Microservices (NIM), a set of performance-optimized, portable microservices designed to accelerate and simplify the deployment of AI models. Those containerized GPU-accelerated pretrained, fine-tuned, and customized models are ideally suited to be self-hosted and deployed on the Lenovo Hybrid AI 289 platform.
The ever-growing catalog of NIM microservices contains models for a wide range of AI use cases, from chatbot assistants to computer vision models for video processing. The image below shows some of the NIM microservices, organized by use case.
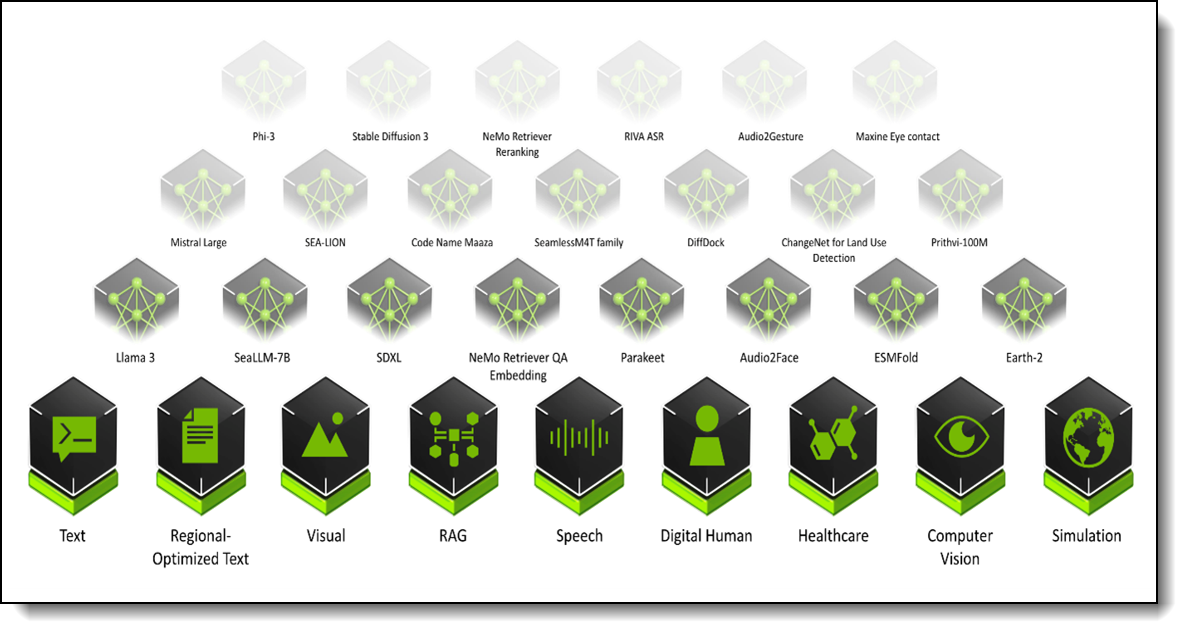
Figure 18. NVIDIA AI Enterprise software stack
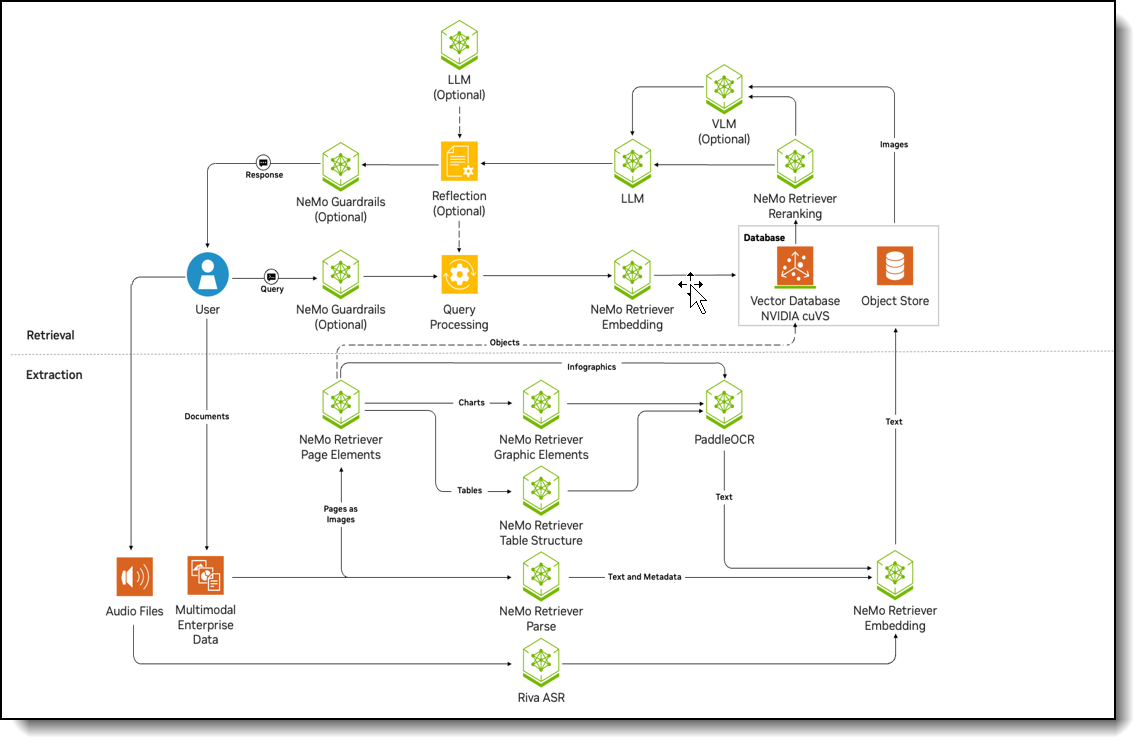
Figure 19. NVIDIA RAG Blueprint
This blueprint outlines the workflow for a system that uses a Retrieval-Augmented Generation (RAG) model. The process can be broken down into two main parts: data ingestion and the user query pipeline.
Data Ingestion
First, unstructured data is fed into the system through the /documents API via the Ingestor server microservice. This service preprocesses the data, divides it into manageable chunks, and then uses the Nvingest microservice to store these chunks in the Milvus Vector Database.
User Query Pipeline
The user's experience begins with the RAG Playground UI or through direct API calls.
- Query Processing: A user's query is sent to the RAG server microservice (built on LangChain) via the /generate API. An optional Query Rewriter component can refine the query for better search results. NeMo Guardrails can also be enabled at this stage to filter out inappropriate queries.
- Document Retrieval: The refined query is sent to the Retriever module, which queries the Milvus Vector Database. This database holds data embeddings created by the NeMo Retriever Embedding microservice. The retriever identifies the top K most relevant chunks of information.
- Reranking (Optional): The top K chunks are passed to the NeMo Retriever reranking microservice. This component further refines the results, selecting the top N most relevant chunks for improved precision.
- Response Generation: The top N chunks are then injected into a prompt and sent to the Response Generation module. This module uses the NeMo LLM inference microservice to generate a natural language response. An optional reflection module can make additional calls to the Large Language Model (LLM) to verify the response's accuracy based on the retrieved context. NeMo Guardrails can also be applied here to ensure the final output is safe and non-toxic.
- Response Delivery: Finally, the generated response is sent back to the RAG Playground. The user can then view the answer and see the source citations for the retrieved information.
This modular design ensures efficient query processing, accurate retrieval of information, and easy customization.
AI Services
The services offered with the Lenovo Hybrid AI platforms are specifically designed to enable broad adoption of AI in the Enterprise. This enables both Lenovo AI Partners and Lenovo Professional Services to accelerate deployment and provide enterprises with the fastest time to production.
The Lenovo AI services offered alongside the Lenovo Hybrid AI platforms enable customers to overcome the barriers they face in realizing ROI from AI investments by providing critical expertise needed to accelerate business outcomes and maximum efficiency. Leveraging Lenovo AI expertise, Lenovo’s advanced partner ecosystem, and industry leading technology we help customers realize the benefits of AI faster. Unlike providers that tie GPU services to proprietary stacks, Lenovo takes a services-first approach, helping enterprises maximize existing investments and scale AI on their own terms.
The two current services offerings broken down to the right of the AI Factory and AI Foundation layers found in Figure 4 below. AI Fast Start Services provide use case development and validation for agentic AI and GenAI applications. The GPU Advance Services provide the foundation needed for AI use case development, including AI factory design, deployment of the software and firmware stack, and setup of orchestration software. Optionally, TruScale RedHat OpenShift service can be added for those wanting to use OpenShift on RHEL. All services are flexible to meet the unique needs of different organizations while adhering to Lenovo's Reference Architectures and Platform Guides. Figure 4 shows some of the possible combinations of software and orchestration that are found in this Reference Architecture.
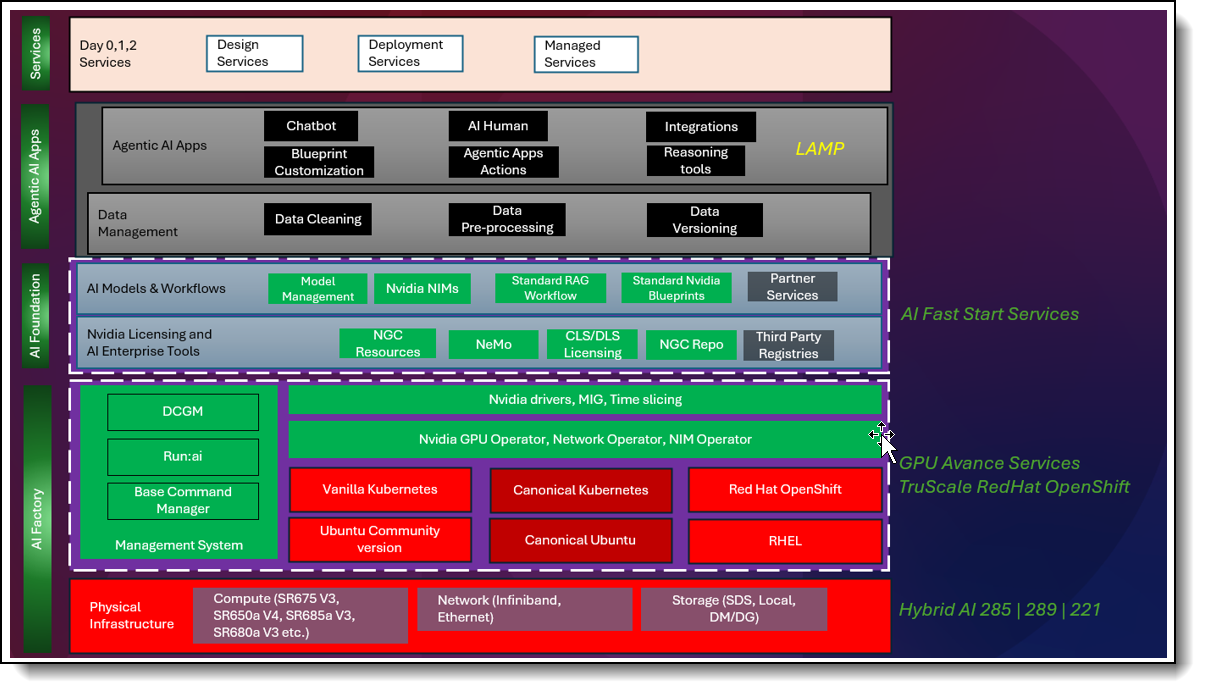
Service & Support Offerings
The following table lists the Service and support offerings
GPU Plan & Design Services
Lenovo offers advisory services to support organizations in planning and optimizing high-performance GPU workloads, including assessment of current infrastructure and identifying intended use cases.
This service helps customers with:
- Planning for optimal GPU utilization
- Aligning business and tech strategy
- Workload assessment
- deployment strategy
- Architecture and design
- Solution sizing and technology selection
- High-level architecture
The outcomes of the GPU Plan & Design Services are reduced risk and access to proven best practices. Improved performance and an optimised infrastructure at the outset build a solid base that is future-proofed to accommodate growth.
GPU Configuration and Deployment Services
Configuration and deployment services help organizations accelerate their timeline. By providing installation and setup for the complete Lenovo recommended software stack for AI, this service acts as the engine of the solution, significantly accelerating the time to value.
Lenovo deployment services help provide the fastest time to first token for an enterprise building their Hybrid AI factory. The GPU advanced configuration and deployment services provide expert guidance on software and hardware components to get your AI factory up and running, including:
- Operating system
- Kubernetes
- GPU configuration
- DDN storage configuration
With this service Lenovo enables deployment of the Lenovo Hybrid AI configurations, from a single node to multi-node, with customizable AI software stack and services. Leveraging our deep relationship with NVIDIA, we can fine-tune the GPU performance to precisely match the customer’s workload requirements.
Lenovo enables customers to overcome skills gaps to fully utilize their GPU configurations and boost the performance of their most challenging workloads. Lenovo also helps upskill a diverse customer team with knowledge transfer from Lenovo experts, working within the framework of our scalable, customizable Lenovo Hybrid AI architectures deliver end-to-end solutions designed to accelerate enterprise AI adoption.
Customers will receive a low-level design of the configuration as well as knowledge transfer from Lenovo’s experts
GPU Managed Services
Lenovo provides managed NVIDIA-based GPU systems that can address customer needs on an ongoing basis. This includes support, security & compliance, and business functions.
Customers can consistently maintain peak performance of their GPU infrastructure through the following support:
- L1 support for the GPU and NVIDIA AI Enterprise software (if applicable)
- Security and compliance verification
- Ongoing GPU performance monitoring and tuning with logging and alerts
- Backup and restore of the management components and configuration
GPU Managed Services seamlessly scales with the organization and giving greater visibility and monitoring of performance. Additionally these services provide vulnerability patching to stay ahead of risks which helps free up developers and data scientists to focus on innovation.
Lenovo AI Center of Excellence
In addition to the choice of utilizing Lenovo EveryScale Infrastructure framework for the Enterprise AI platform to ensure tested and warranted interoperability, Lenovo operates an AI Lab and CoE at the headquarters in Morrisville, North Carolina, USA to test and enable AI applications and use cases on the Lenovo EveryScale AI platform.
The AI Lab environment allows customers and partners to execute proof of concepts for their use cases or test their AI middleware or applications. It is configured as a diverse AI platform with a range of systems and GPU options, including NVIDIA L40S and NVIDIA HGX8 H200.
The software environment utilizes Canonical Ubuntu Linux along with Canonical MicroK8s to offer a multi-tenant Kubernetes environment. This setup allows customers and partners to schedule their respective test containers effectively.
Lenovo AI Innovators
Lenovo Hybrid AI platforms offer the necessary infrastructure for a customer’s hybrid AI factory. To fully leverage the potential of AI integration within business processes and operations, software providers, both large and small, are developing specialized AI applications tailored to a wide array of use cases.
To support the adoption of those AI applications, Lenovo continues to invest in and extend its AI Innovators Program to help organizations gain access to enterprise AI by partnering with more than 50 of the industry’s leading software providers.
Partners of the Lenovo AI Innovators Program get access to our AI Discover Labs, where they validate their solutions and jointly support Proof of Concepts and Customer engagements.
LAII provides customers and channel partners with a range of validated solutions across various vertical use cases, such as for Retail or Public Security. These solutions are designed to facilitate the quick and safe deployment of AI solutions that optimally address the business requirements.
The following is a selection of case studies involving Lenovo customers implementing an AI solution:
- Kroeger (Retail) – Reducing Customer friction and loss prevention
- Peak (Logistics) – Streamlining supply chain ops for fast and efficient deliveries
- Bikal (AI at Scale) – Delivering shared AI platform for education
- VSAAS (Smart Cities) – Enabling accurate and effective public security
Lenovo Validated Designs
Lenovo Validated Designs (LVDs) are pre-tested, optimized solution designs enabling reliability, scalability, and efficiency in specific workloads or industries. These solutions integrate Lenovo hardware like ThinkSystem servers, storage, and networking with software and best practices to solve common IT challenges. Developed with technology partners such as VMware, Intel, and Red Hat, LVDs ensure performance, compatibility, and easy deployment through rigorous validation.
Lenovo Validated Designs are intended to simplify the planning, implementation, and management of complex IT infrastructures. They provide detailed guidance, including architectural overviews, component models, deployment considerations, and bills of materials, tailored to specific use cases such as artificial intelligence (AI), big data analytics, cloud computing, virtualization, retail, or smart manufacturing. By offering a pretested solution, LVDs aim to reduce risk, accelerate deployment, and assist organizations in achieving faster time-to-value for their IT investments.
Lenovo Hybrid AI platforms act as infrastructure frameworks for LVDs addressing data center-based AI solutions. They provide the hardware/software reference architecture, optionally Lenovo EveryScale integrated solution delivery method, and general sizing guidelines.
Lenovo TruScale
Lenovo TruScale XaaS is your set of flexible IT services that makes everything easier. Streamline IT procurement, simplify infrastructure and device management, and pay only for what you use – so your business is free to grow and go anywhere.
Lenovo TruScale is the unified solution that gives you simplified access to:
- The industry’s broadest portfolio – from pocket to cloud – all delivered as a service
- A single-contract framework for full visibility and accountability
- The global scale to rapidly and securely build teams from anywhere
- Flexible fixed and metered pay-as-you-go models with minimal upfront cost
- The growth-driving combination of hardware, software, infrastructure, and solutions – all from one single provider with one point of accountability.
For information about Lenovo TruScale offerings that are available in your region, contact your local Lenovo sales representative or business partner.
Lenovo Financial Services
Why wait to obtain the technology you need now? No payments for 90 days and predictable, low monthly payments make it easy to budget for your Lenovo solution.
- Flexible
Our in-depth knowledge of the products, services and various market segments allows us to offer greater flexibility in structures, documentation and end of lease options.
- 100% Solution Financing
Financing your entire solution including hardware, software, and services, ensures more predictability in your project planning with fixed, manageable payments and low monthly payments.
- Device as a Service (DaaS)
Leverage latest technology to advance your business. Customized solutions aligned to your needs. Flexibility to add equipment to support growth. Protect your technology with Lenovo's Premier Support service.
- 24/7 Asset management
Manage your financed solutions with electronic access to your lease documents, payment histories, invoices and asset information.
- Fair Market Value (FMV) and $1 Purchase Option Leases
Maximize your purchasing power with our lowest cost option. An FMV lease offers lower monthly payments than loans or lease-to-own financing. Think of an FMV lease as a rental. You have the flexibility at the end of the lease term to return the equipment, continue leasing it, or purchase it for the fair market value. In a $1 Out Purchase Option lease, you own the equipment. It is a good option when you are confident you will use the equipment for an extended period beyond the finance term. Both lease types have merits depending on your needs. We can help you determine which option will best meet your technological and budgetary goals.
Ask your Lenovo Financial Services representative about this promotion and how to submit a credit application. For the majority of credit applicants, we have enough information to deliver an instant decision and send a notification within minutes.
Bill of Materials
Solution IDs on Lenovo Data Center Solution Configurator
For the most detailed configurations and up to date parts, please see the Hybrid AI 289 section in Deployment Ready Solutions on Lenovo Data Center Solution Configurator: Click here
Example BoMs for Deployment Sizes
Consult the full BoM for per-system to determine the exact quantities for each deployment size. Outlined below is a high level overview of each deployment size will require.
3 SU Example Bill of Materials
- 12x Lenovo ThinkSystem SR685a V3 with HGX H200 GPU
- 8x Lenovo ThinkSystem SR655 V3
- 2x NVIDIA SN5610 Switches
- 3x NVIDIA SN2201 Switches
- 4x Onyx Heavy Duty Rack Cabinet
8 SU Example Bill of Materials
- 32x Lenovo ThinkSystem SR685a V3 with HGX H200 GPU
- 8x Lenovo ThinkSystem SR655 V3
- 8x NVIDIA SN5610 Switches
- 8x NVIDIA SN2201 Switches
- 9x Onyx Heavy Duty Rack Cabinet
32 SU Example Bill of Materials
- 128x Lenovo ThinkSystem SR685a V3 with HGX H200 GPU
- 8x Lenovo ThinkSystem SR655 V3
- 49x NVIDIA SN5610 Switches
- 32x NVIDIA SN2201 Switches
- 37x Onyx Heavy Duty Rack Cabinet
Storage is optional and not included in this BoM.
Per System Bill of Materials
In this section:
ThinkSystem SR685a V3 BOM
ThinkSystem SR680a V3 BOM
ThinkSystem SR780a V3
ThinkSystem SR780a V3 B200 BoM
ThinkSystem SR655 V3 BoM
NVIDIA SN2201 Switch BoM
Rack Cabinet BoM
Seller training courses
The following sales training courses are offered for employees and partners (login required). Courses are listed in date order.
-
VTT AI: Introducing the Lenovo Hybrid AI 285 Platform with Cisco Networking
2025-11-04 | 36 minutes | Partners Only
DetailsVTT AI: Introducing the Lenovo Hybrid AI 285 Platform with Cisco Networking
The Lenovo Hybrid AI 285 Platform enables enterprises of all sizes to quickly deploy AI infrastructures supporting use cases as either new greenfield environments or as an extension to current infrastructures.
Published: 2025-11-04
This session will describe the hardware architecture changes required to leverage Cisco networking hardware and the Cisco Nexus Dashboard within the Hybrid AI 285 Platform.
Topics include:
- Value propositions for the Hybrid AI 285 platform
- Updates for the Hybrid AI 285 platform
- Leveraging Cisco networking with the 285 platform
- Future plans for the 285 platform
Length: 36 minutes
Course code: DVAI220_PStart the training:
Partner link: Lenovo 360 Learning Center
-
Partner Technical Webinar - Lenovo AI Hybrid Factory offerings
2025-10-13 | 50 minutes | Employees and Partners
DetailsPartner Technical Webinar - Lenovo AI Hybrid Factory offerings
In this 50-minute replay, Pierce Beary, Lenovo Senior AI Solution Manager, review the Lenovo AI Factory offerings for the data center. Pierce showed how Lenovo is simplifying the AI compute needs for the data center with the AI 281, AI 285 and AI 289 platforms based on the NVIDIA AI Enterprise Reference Architecture.
Published: 2025-10-13
Tags: Artificial Intelligence (AI)
Length: 50 minutes
Course code: OCT1025Start the training:
Employee link: Grow@Lenovo
Partner link: Lenovo 360 Learning Center
-
Lenovo VTT Cloud Architecture: Empowering AI Innovation with NVIDIA RTX Pro 6000 and Lenovo Hybrid AI Services
2025-09-18 | 68 minutes | Employees Only
DetailsLenovo VTT Cloud Architecture: Empowering AI Innovation with NVIDIA RTX Pro 6000 and Lenovo Hybrid AI Services
Join Dinesh Tripathi, Lenovo Technical Team Lead for GenAI and Jose Carlos Huescas, Lenovo HPC & AI Product Manager for an in-depth, interactive technical webinar. This session will explore how to effectively position the NVIDIA RTX PRO 6000 Blackwell Server Edition in AI and visualization workflows, with a focus on real-world applications and customer value.
Published: 2025-09-18
We’ll cover:
- NVIDIA RTX PRO 6000 Blackwell Overview: Key specs, performance benchmarks, and use cases in AI, rendering, and simulation.
- Positioning Strategy: How to align NVIDIA RTX PRO 6000 with customer needs across industries like healthcare, manufacturing, and media.
- Lenovo Hybrid AI 285 Services: Dive into Lenovo’s Hybrid AI 285 architecture and learn how it supports scalable AI deployments from edge to cloud.
Whether you're enabling AI solutions or guiding customers through infrastructure decisions, this session will equip you with the insights and tools to drive impactful conversations.
Tags: Industry solutions, SMB, Services, Technical Sales, Technology solutions
Length: 68 minutes
Course code: DVCLD227Start the training:
Employee link: Grow@Lenovo
-
VTT AI: Introducing The Lenovo Hybrid AI 285 Platform with Cisco Networking
2025-08-26 | 54 minutes | Employees Only
DetailsVTT AI: Introducing The Lenovo Hybrid AI 285 Platform with Cisco Networking
Please view this session as Pierce Beary, Sr. AI Solution Manager, ISG ESMB Segment and AI explains:
Published: 2025-08-26
- Value propositions for the Hybrid AI 285 platform
- Updates for the Hybrid AI 285 platform
- Leveraging Cisco networking with the 285 platform
- Future plans for the 285 platform
Tags: Artificial Intelligence (AI), Technical Sales, ThinkSystem
Length: 54 minutes
Course code: DVAI220Start the training:
Employee link: Grow@Lenovo
-
VTT AI: Introducing the Lenovo Hybrid AI 285 Platform April 2025
2025-04-30 | 60 minutes | Employees Only
DetailsVTT AI: Introducing the Lenovo Hybrid AI 285 Platform April 2025
The Lenovo Hybrid AI 285 Platform enables enterprises of all sizes to quickly deploy AI infrastructures supporting use cases as either new greenfield environments or as an extension to current infrastructures. The 285 Platform enables the use of the NVIDIA AI Enterprise software stack. The AI Hybrid 285 platform is the perfect foundation supporting Lenovo Validated Designs.
Published: 2025-04-30
• Technical overview of the Hybrid AI 285 platform
• AI Hybrid platforms as infrastructure frameworks for LVDs addressing data center-based AI solutions.
• Accelerate AI adoption and reduce deployment risks
Tags: Artificial Intelligence (AI), Nvidia, Technical Sales, Lenovo Hybrid AI 285
Length: 60 minutes
Course code: DVAI215Start the training:
Employee link: Grow@Lenovo
Related publications and links
For more information, see these resources:
- Lenovo EveryScale support page:
https://datacentersupport.lenovo.com/us/en/solutions/ht505184 - x-config configurator:
https://lesc.lenovo.com/products/hardware/configurator/worldwide/bhui/asit/x-config.jnlp - Implementing AI Workloads using NVIDIA GPUs on ThinkSystem Servers:
https://lenovopress.lenovo.com/lp1928-implementing-ai-workloads-using-nvidia-gpus-on-thinksystem-servers - Making LLMs Work for Enterprise Part 3: GPT Fine-Tuning for RAG:
https://lenovopress.lenovo.com/lp1955-making-llms-work-for-enterprise-part-3-gpt-fine-tuning-for-rag - Lenovo to Deliver Enterprise AI Compute for NetApp AIPod Through Collaboration with NetApp and NVIDIA
https://lenovopress.lenovo.com/lp1962-lenovo-to-deliver-enterprise-ai-compute-for-netapp-aipod-nvidia
Trademarks
Lenovo and the Lenovo logo are trademarks or registered trademarks of Lenovo in the United States, other countries, or both. A current list of Lenovo trademarks is available on the Web at https://www.lenovo.com/us/en/legal/copytrade/.
The following terms are trademarks of Lenovo in the United States, other countries, or both:
Lenovo®
AnyBay®
From Exascale to EveryScale®
ThinkSystem®
XClarity®
The following terms are trademarks of other companies:
AMD and AMD EPYC™ are trademarks of Advanced Micro Devices, Inc.
Intel® and Xeon® are trademarks of Intel Corporation or its subsidiaries.
Linux® is the trademark of Linus Torvalds in the U.S. and other countries.
Other company, product, or service names may be trademarks or service marks of others.
Configure and Buy
Please select a locale
Full Change History
Course Detail
Employees Only Content
The content in this document with a is only visible to employees who are logged in. Logon using your Lenovo ITcode and password via Lenovo single-signon (SSO).
The author of the document has determined that this content is classified as Lenovo Internal and should not be normally be made available to people who are not employees or contractors. This includes partners, customers, and competitors. The reasons may vary and you should reach out to the authors of the document for clarification, if needed. Be cautious about sharing this content with others as it may contain sensitive information.
Any visitor to the Lenovo Press web site who is not logged on will not be able to see this employee-only content. This content is excluded from search engine indexes and will not appear in any search results.
For all users, including logged-in employees, this employee-only content does not appear in the PDF version of this document.
This functionality is cookie based. The web site will normally remember your login state between browser sessions, however, if you clear cookies at the end of a session or work in an Incognito/Private browser window, then you will need to log in each time.
If you have any questions about this feature of the Lenovo Press web, please email David Watts at dwatts@lenovo.com.





